gemini/orchestration/intro_langchain_gemini.ipynb (1,476 lines of code) (raw):
{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "_1uzXWPtI1b_"
},
"outputs": [],
"source": [
"# Copyright 2024 Google LLC\n",
"#\n",
"# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
"# you may not use this file except in compliance with the License.\n",
"# You may obtain a copy of the License at\n",
"#\n",
"# https://www.apache.org/licenses/LICENSE-2.0\n",
"#\n",
"# Unless required by applicable law or agreed to in writing, software\n",
"# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
"# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
"# See the License for the specific language governing permissions and\n",
"# limitations under the License."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "359697d5"
},
"source": [
"# Getting Started with LangChain 🦜️🔗 + Gemini API in Vertex AI\n",
"\n",
"<table align=\"left\">\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://colab.research.google.com/github/GoogleCloudPlatform/generative-ai/blob/main/gemini/orchestration/intro_langchain_gemini.ipynb\">\n",
" <img src=\"https://cloud.google.com/ml-engine/images/colab-logo-32px.png\" alt=\"Google Colaboratory logo\"><br> Run in Colab\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://console.cloud.google.com/vertex-ai/colab/import/https:%2F%2Fraw.githubusercontent.com%2FGoogleCloudPlatform%2Fgenerative-ai%2Fmain%2Fgemini%2Forchestration%2Fintro_langchain_gemini.ipynb\">\n",
" <img width=\"32px\" src=\"https://lh3.googleusercontent.com/JmcxdQi-qOpctIvWKgPtrzZdJJK-J3sWE1RsfjZNwshCFgE_9fULcNpuXYTilIR2hjwN\" alt=\"Google Cloud Colab Enterprise logo\"><br> Run in Colab Enterprise\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/orchestration/intro_langchain_gemini.ipynb\">\n",
" <img src=\"https://cloud.google.com/ml-engine/images/github-logo-32px.png\" alt=\"GitHub logo\"><br> View on GitHub\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://console.cloud.google.com/vertex-ai/workbench/deploy-notebook?download_url=https://raw.githubusercontent.com/GoogleCloudPlatform/generative-ai/main/gemini/orchestration/intro_langchain_gemini.ipynb\">\n",
" <img src=\"https://lh3.googleusercontent.com/UiNooY4LUgW_oTvpsNhPpQzsstV5W8F7rYgxgGBD85cWJoLmrOzhVs_ksK_vgx40SHs7jCqkTkCk=e14-rj-sc0xffffff-h130-w32\" alt=\"Vertex AI logo\"><br> Open in Vertex AI Workbench\n",
" </a>\n",
" </td>\n",
"</table>\n",
"\n",
"<div style=\"clear: both;\"></div>\n",
"\n",
"<b>Share to:</b>\n",
"\n",
"<a href=\"https://www.linkedin.com/sharing/share-offsite/?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/orchestration/intro_langchain_gemini.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/8/81/LinkedIn_icon.svg\" alt=\"LinkedIn logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://bsky.app/intent/compose?text=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/orchestration/intro_langchain_gemini.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/7/7a/Bluesky_Logo.svg\" alt=\"Bluesky logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://twitter.com/intent/tweet?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/orchestration/intro_langchain_gemini.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/5/5a/X_icon_2.svg\" alt=\"X logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://reddit.com/submit?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/orchestration/intro_langchain_gemini.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://redditinc.com/hubfs/Reddit%20Inc/Brand/Reddit_Logo.png\" alt=\"Reddit logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://www.facebook.com/sharer/sharer.php?u=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/orchestration/intro_langchain_gemini.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/5/51/Facebook_f_logo_%282019%29.svg\" alt=\"Facebook logo\">\n",
"</a> \n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "b24d7ab7a7a5"
},
"source": [
"| Authors |\n",
"| --- |\n",
"| [Rajesh Thallam](https://github.com/RajeshThallam) |\n",
"| [Holt Skinner](https://github.com/holtskinner) |"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "11d788b0"
},
"source": [
"### **What is LangChain?**\n",
"\n",
"> LangChain is a framework for developing applications powered by large language models (LLMs).\n",
"\n",
"**TL;DR** LangChain makes the complicated parts of working & building with language models easier. It helps do this in two ways:\n",
"\n",
"1. **Integration** - Bring external data, such as your files, other applications, and API data, to LLMs\n",
"2. **Agents** - Allows LLMs to interact with its environment via decision making and use LLMs to help decide which action to take next"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Fpilrb5XVT_k"
},
"source": [
"To build effective Generative AI applications, it is key to enable LLMs to interact with external systems. This makes models data-aware and agentic, meaning they can understand, reason, and use data to take action in a meaningful way. The external systems could be public data corpus, private knowledge repositories, databases, applications, APIs, or access to the public internet via Google Search.\n",
"\n",
"Here are a few patterns where LLMs can be augmented with other systems:\n",
"\n",
"- Convert natural language to SQL, executing the SQL on database, analyze and present the results\n",
"- Calling an external webhook or API based on the user query\n",
"- Synthesize outputs from multiple models, or chain the models in a specific order\n",
"\n",
"It may look trivial to plumb these calls together and orchestrate them but it becomes a mundane task to write glue code again and again e.g. for every different data connector or a new model. That's where LangChain comes in!\n",
"\n",
"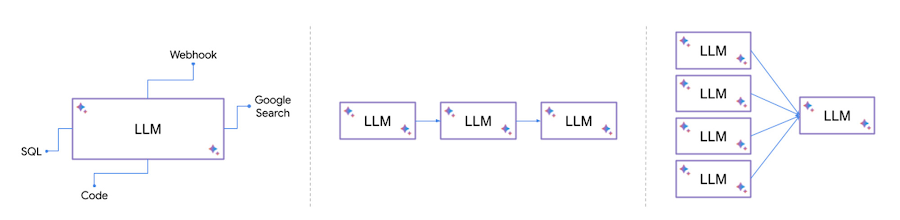"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "aATSgLjXVVY0"
},
"source": [
"### **Why LangChain?**\n",
"\n",
"LangChain's modular implementation of components and common patterns combining these components makes it easier to build complex applications based on LLMs. LangChain enables these models to connect to data sources and systems as agents to take action.\n",
"\n",
"1. **Components** are abstractions that works to bring external data, such as your documents, databases, applications,APIs to language models. LangChain makes it easy to swap out abstractions and components necessary to work with LLMs.\n",
"\n",
"2. **Agents** enable language models to communicate with its environment, where the model then decides the next action to take. LangChain provides out of the box support for using and customizing 'chains' - a series of actions strung together.\n",
"\n",
"Though LLMs can be straightforward (text-in, text-out) you'll quickly run into friction points that LangChain helps with once you develop more complicated applications.\n",
"\n",
"### LangChain & Vertex AI\n",
"\n",
"[Vertex AI Generative AI models](https://cloud.google.com/vertex-ai/docs/generative-ai/learn/overview) — Gemini and Embeddings — are officially integrated with the [LangChain Python SDK](https://python.langchain.com/en/latest/index.html), making it convenient to build applications using Gemini models with the ease of use and flexibility of LangChain.\n",
"\n",
"- [LangChain Google Integrations](https://python.langchain.com/v0.2/docs/integrations/platforms/google/)\n",
"\n",
"---\n",
"\n",
"_Note: This notebook does not cover all aspects of LangChain. Its contents have been curated to get you to building & impact as quick as possible. For more, please check out [LangChain Conceptual Documentation](https://docs.langchain.com/docs/)_\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "50b19d12"
},
"source": [
"## Objectives\n",
"\n",
"This notebook provides an introductory understanding of [LangChain](https://langchain.com/) components and use cases of LangChain with the Gemini API in Vertex AI.\n",
"\n",
"- Introduce LangChain components\n",
"- Showcase LangChain + Gemini API in Vertex AI - Text, Chat and Embedding\n",
"- Summarizing a large text\n",
"- Question/Answering from PDF (retrieval based)\n",
"- Chain LLMs with Google Search\n",
"\n",
"---\n",
"\n",
"**References:**\n",
"\n",
"- Adapted from [LangChain Cookbook](https://github.com/gkamradt/langchain-tutorials) from [Greg Kamradt](https://twitter.com/GregKamradt)\n",
"- [LangChain Conceptual Documentation](https://docs.langchain.com/docs/)\n",
"- [LangChain Python Documentation](https://python.langchain.com/en/latest/)\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "e985f332"
},
"source": [
"### Costs\n",
"\n",
"This tutorial uses billable components of Google Cloud:\n",
"\n",
"- Vertex AI\n",
"\n",
"Learn about [Vertex AI pricing](https://cloud.google.com/vertex-ai/pricing),\n",
"and use the [Pricing Calculator](https://cloud.google.com/products/calculator/)\n",
"to generate a cost estimate based on your projected usage.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ohPUPez8imvE"
},
"outputs": [],
"source": [
"# Install Vertex AI SDK, LangChain and dependencies\n",
"%pip install --upgrade --quiet google-cloud-aiplatform langchain langchain-core langchain-text-splitters langchain-google-vertexai langchain-community faiss-cpu langchain-chroma pypdf"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "034fe628"
},
"source": [
"### Authenticating your notebook environment\n",
"\n",
"- If you are using **Colab** to run this notebook, run the cell below and continue.\n",
"- If you are using **Vertex AI Workbench**, check out the setup instructions [here](https://github.com/GoogleCloudPlatform/generative-ai/tree/main/setup-env)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "6d83f50a3d3f"
},
"outputs": [],
"source": [
"import sys\n",
"\n",
"if \"google.colab\" in sys.modules:\n",
" from google.colab import auth\n",
"\n",
" auth.authenticate_user()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "5f33c406cb7c"
},
"source": [
"- If you are running this notebook in a local development environment:\n",
" - Install the [Google Cloud SDK](https://cloud.google.com/sdk).\n",
" - Obtain authentication credentials. Create local credentials by running the following command and following the oauth2 flow (read more about the command [here](https://cloud.google.com/sdk/gcloud/reference/beta/auth/application-default/login)):\n",
"\n",
" ```bash\n",
" gcloud auth application-default login\n",
" ```"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "a92ac8ea"
},
"source": [
"### Import libraries\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "f7aedf28aa5e"
},
"source": [
"**Colab only:** Run the following cell to initialize the Vertex AI SDK. For Vertex AI Workbench, you don't need to run this."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "4f6ab09a187c"
},
"outputs": [],
"source": [
"import os\n",
"\n",
"PROJECT_ID = \"[your-project-id]\" # @param {type: \"string\", placeholder: \"[your-project-id]\", isTemplate: true}\n",
"if not PROJECT_ID or PROJECT_ID == \"[your-project-id]\":\n",
" PROJECT_ID = str(os.environ.get(\"GOOGLE_CLOUD_PROJECT\"))\n",
"\n",
"LOCATION = os.environ.get(\"GOOGLE_CLOUD_REGION\", \"us-central1\")\n",
"\n",
"import vertexai\n",
"\n",
"# Initialize Vertex AI SDK\n",
"vertexai.init(project=PROJECT_ID, location=LOCATION)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Smo-7TpE4B22"
},
"outputs": [],
"source": [
"from langchain.chains import (\n",
" ConversationChain,\n",
" LLMChain,\n",
" RetrievalQA,\n",
" SimpleSequentialChain,\n",
")\n",
"from langchain.chains.summarize import load_summarize_chain\n",
"from langchain.memory import ConversationBufferMemory\n",
"from langchain.output_parsers import ResponseSchema, StructuredOutputParser\n",
"from langchain_chroma import Chroma\n",
"from langchain_community.document_loaders import PyPDFLoader, WebBaseLoader\n",
"from langchain_community.vectorstores import FAISS\n",
"from langchain_core.documents import Document\n",
"from langchain_core.example_selectors import SemanticSimilarityExampleSelector\n",
"from langchain_core.messages import HumanMessage, SystemMessage\n",
"from langchain_core.prompts import PromptTemplate\n",
"from langchain_core.prompts.few_shot import FewShotPromptTemplate\n",
"from langchain_google_vertexai import ChatVertexAI, VertexAI, VertexAIEmbeddings\n",
"from langchain_text_splitters import RecursiveCharacterTextSplitter"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "3dd3a375d3b6"
},
"source": [
"Define LangChain Models using the Gemini API in Vertex AI for Text, Chat and Vertex AI Embeddings for Text\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "eVpPcvsrkzCk"
},
"outputs": [],
"source": [
"# LLM model\n",
"llm = VertexAI(\n",
" model_name=\"gemini-2.0-flash\",\n",
" verbose=True,\n",
")\n",
"\n",
"# Chat\n",
"chat = ChatVertexAI(model=\"gemini-2.0-flash\")\n",
"\n",
"# Embedding\n",
"embeddings = VertexAIEmbeddings(\"text-embedding-005\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "05bb564d"
},
"source": [
"## LangChain Components\n",
"\n",
"Let's take a quick tour of LangChain framework and concepts to be aware of. LangChain offers a variety of modules that can be used to create language model applications. These modules can be combined to create more complex applications, or can be used individually for simpler applications.\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "lyGZZEWlZOe0"
},
"source": [
"- **Models** are the building block of LangChain providing an interface to different types of AI models. Large Language Models (LLMs), Chat and Text Embeddings models are supported model types.\n",
"- **Prompts** refers to the input to the model, which is typically constructed from multiple components. LangChain provides interfaces to construct and work with prompts easily - Prompt Templates, Example Selectors and Output Parsers.\n",
"- **Memory** provides a construct for storing and retrieving messages during a conversation which can be either short term or long term.\n",
"- **Indexes** help LLMs interact with documents by providing a way to structure them. LangChain provides Document Loaders to load documents, Text Splitters to split documents into smaller chunks, Vector Stores to store documents as embeddings, and Retrievers to fetch relevant documents.\n",
"- **Chains** let you combine modular components (or other chains) in a specific order to complete a task.\n",
"- **Agents** are a powerful construct in LangChain allowing LLMs to communicate with external systems via Tools and observe and decide on the best course of action to complete a given task.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "EZfIhJSMjDLV"
},
"source": [
"## Schema - Nuts and Bolts of working with LLMs\n",
"\n",
"### Text\n",
"\n",
"Text is the natural language way to interact with LLMs.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "8e0dc06c"
},
"outputs": [],
"source": [
"# You'll be working with simple strings (that'll soon grow in complexity!)\n",
"my_text = \"What day comes after Friday?\"\n",
"\n",
"llm.invoke(my_text)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "2f39eb39"
},
"source": [
"### Chat Messages\n",
"\n",
"Chat is like text, but specified with a message type (System, Human, AI)\n",
"\n",
"- **System** - Helpful context that tells the AI what to do\n",
"- **Human** - Messages intended to represent the user\n",
"- **AI** - Messages showing what the AI responded with\n",
"\n",
"For more information, see [LangChain Documentation for Chat Models](https://python.langchain.com/docs/modules/model_io/chat).\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "qhQOijKAt1ta"
},
"outputs": [],
"source": [
"chat.invoke([HumanMessage(content=\"Hello\")])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "878d6a36"
},
"outputs": [],
"source": [
"res = chat.invoke(\n",
" [\n",
" SystemMessage(\n",
" content=\"You are a nice AI bot that helps a user figure out what to eat in one short sentence\"\n",
" ),\n",
" HumanMessage(content=\"I like tomatoes, what should I eat?\"),\n",
" ]\n",
")\n",
"\n",
"print(res.content)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "0a425aaa"
},
"source": [
"You can also pass more chat history w/ responses from the AI\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "3bNQxPln7wC0"
},
"outputs": [],
"source": [
"res = chat.invoke(\n",
" [\n",
" HumanMessage(\n",
" content=\"What are the ingredients required for making a tomato sandwich?\"\n",
" )\n",
" ]\n",
")\n",
"print(res.content)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "66bf9634"
},
"source": [
"### Documents\n",
"\n",
"Document in LangChain refers to an unstructured text consisting of `page_content` referring to the content of the data and `metadata` (data describing attributes of page content).\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "150e8759"
},
"outputs": [],
"source": [
"Document(\n",
" page_content=\"This is my document. It is full of text that I've gathered from other places\",\n",
" metadata={\n",
" \"my_document_id\": 234234,\n",
" \"my_document_source\": \"The LangChain Papers\",\n",
" \"my_document_create_time\": 1680013019,\n",
" },\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "c2b70f23"
},
"source": [
"### Text Embedding Model\n",
"\n",
"[Embeddings](https://cloud.google.com/blog/topics/developers-practitioners/meet-ais-multitool-vector-embeddings) are a way of representing data–almost any kind of data, like text, images, videos, users, music, whatever–as points in space where the locations of those points in space are semantically meaningful. Embeddings transform your text into a vector (a series of numbers that hold the semantic 'meaning' of your text). Vectors are often used when comparing two pieces of text together. An [embedding](https://developers.google.com/machine-learning/crash-course/embeddings/video-lecture) is a relatively low-dimensional space into which you can translate high-dimensional vectors.\n",
"\n",
"[LangChain Text Embedding Model](https://python.langchain.com/v0.2/docs/how_to/embed_text) is integrated with [Vertex AI Embedding API for Text](https://cloud.google.com/vertex-ai/docs/generative-ai/embeddings/get-text-embeddings).\n",
"\n",
"_BTW: Semantic means 'relating to meaning in language or logic.'_\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "a2c85e7e"
},
"outputs": [],
"source": [
"text = \"Hi! It's time for the beach\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ddc5a368"
},
"outputs": [],
"source": [
"text_embedding = embeddings.embed_query(text)\n",
"print(f\"Your embedding is length {len(text_embedding)}\")\n",
"print(f\"Here's a sample: {text_embedding[:5]}...\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "c38fe99f"
},
"source": [
"## Prompts\n",
"\n",
"Prompts are text used as instructions to your model. For more details have a look at the notebook [Intro to Prompt Design](https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/prompts/intro_prompt_design.ipynb).\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "PrvHxWMidmTU"
},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Today is Monday, tomorrow is Wednesday.\n",
"\n",
"What is wrong with that statement?\n",
"\"\"\"\n",
"\n",
"llm.invoke(prompt)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "74988254"
},
"source": [
"### **Prompt Template**\n",
"\n",
"[Prompt Template](https://python.langchain.com/v0.1/docs/modules/model_io/#prompt-templates) is an object that helps to create prompts based on a combination of user input, other non-static information and a fixed template string.\n",
"\n",
"Think of it as an [`f-string`](https://realpython.com/python-f-strings/) in Python but for prompts\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "abcc212d"
},
"outputs": [],
"source": [
"# Notice \"location\" below, that is a placeholder for another value later\n",
"template = \"\"\"\n",
"I really want to travel to {location}. What should I do there?\n",
"\n",
"Respond in one short sentence\n",
"\"\"\"\n",
"\n",
"prompt = PromptTemplate(\n",
" input_variables=[\"location\"],\n",
" template=template,\n",
")\n",
"\n",
"final_prompt = prompt.format(location=\"Rome\")\n",
"\n",
"output = llm.invoke(final_prompt)\n",
"\n",
"print(f\"Final Prompt: {final_prompt}\")\n",
"print(\"-----------\")\n",
"print(f\"LLM Output: {output}\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ed40bac2"
},
"source": [
"### **Example Selectors**\n",
"\n",
"[Example selectors](https://python.langchain.com/v0.1/docs/modules/model_io/prompts/example_selectors/) are an easy way to select from a series of examples to dynamically place in-context information into your prompt. Often used when the task is nuanced or has a large list of examples.\n",
"\n",
"Check out different types of example selectors [here](https://python.langchain.com/docs/how_to/example_selectors/)\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "aaf36cd9"
},
"outputs": [],
"source": [
"example_prompt = PromptTemplate(\n",
" input_variables=[\"input\", \"output\"],\n",
" template=\"Example Input: {input}\\nExample Output: {output}\",\n",
")\n",
"\n",
"# Examples of locations that nouns are found\n",
"examples = [\n",
" {\"input\": \"pirate\", \"output\": \"ship\"},\n",
" {\"input\": \"pilot\", \"output\": \"plane\"},\n",
" {\"input\": \"driver\", \"output\": \"car\"},\n",
" {\"input\": \"tree\", \"output\": \"ground\"},\n",
" {\"input\": \"bird\", \"output\": \"nest\"},\n",
"]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "12b4798b"
},
"outputs": [],
"source": [
"# SemanticSimilarityExampleSelector will select examples that are similar to your input by semantic meaning\n",
"\n",
"example_selector = SemanticSimilarityExampleSelector.from_examples(\n",
" # This is the list of examples available to select from.\n",
" examples,\n",
" # This is the embedding class used to produce embeddings which are used to measure semantic similarity.\n",
" embeddings,\n",
" # This is the VectorStore class that is used to store the embeddings and do a similarity search over.\n",
" FAISS,\n",
" # This is the number of examples to produce.\n",
" k=2,\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "2cf30107"
},
"outputs": [],
"source": [
"similar_prompt = FewShotPromptTemplate(\n",
" # The object that will help select examples\n",
" example_selector=example_selector,\n",
" # Your prompt\n",
" example_prompt=example_prompt,\n",
" # Customizations that will be added to the top and bottom of your prompt\n",
" prefix=\"Give the location an item is usually found in\",\n",
" suffix=\"Input: {noun}\\nOutput:\",\n",
" # What inputs your prompt will receive\n",
" input_variables=[\"noun\"],\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "369442bb"
},
"outputs": [],
"source": [
"# Select a noun!\n",
"my_noun = \"student\"\n",
"\n",
"print(similar_prompt.format(noun=my_noun))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "9bb910f2"
},
"outputs": [],
"source": [
"llm.invoke(similar_prompt.format(noun=my_noun))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8474c91d"
},
"source": [
"### **Output Parsers**\n",
"\n",
"[Output Parsers](https://python.langchain.com/docs/modules/model_io/output_parsers/) help to format the output of a model. Usually used for structured output.\n",
"\n",
"Two main ideas:\n",
"\n",
"**1. Format Instructions**: An autogenerated prompt that tells the LLM how to format it's response based off desired result\n",
"\n",
"**2. Parser**: A method to extract model's text output into a desired structure (usually json)\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "fa59be3f"
},
"outputs": [],
"source": [
"# How you would like your response structured. This is basically a fancy prompt template\n",
"response_schemas = [\n",
" ResponseSchema(\n",
" name=\"bad_string\", description=\"This a poorly formatted user input string\"\n",
" ),\n",
" ResponseSchema(\n",
" name=\"good_string\", description=\"This is your response, a reformatted response\"\n",
" ),\n",
"]\n",
"\n",
"# How you would like to parse your output\n",
"output_parser = StructuredOutputParser.from_response_schemas(response_schemas)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "d1079f0a"
},
"outputs": [],
"source": [
"# See the prompt template you created for formatting\n",
"format_instructions = output_parser.get_format_instructions()\n",
"print(format_instructions)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "9aaae5be"
},
"outputs": [],
"source": [
"template = \"\"\"\n",
"You will be given a poorly formatted string from a user.\n",
"Reformat it and make sure all the words are spelled correctly including country, city and state names\n",
"\n",
"{format_instructions}\n",
"\n",
"% USER INPUT:\n",
"{user_input}\n",
"\n",
"YOUR RESPONSE:\n",
"\"\"\"\n",
"\n",
"prompt = PromptTemplate(\n",
" input_variables=[\"user_input\"],\n",
" partial_variables={\"format_instructions\": format_instructions},\n",
" template=template,\n",
")\n",
"\n",
"prompt_value = prompt.format(user_input=\"welcom to dbln!\")\n",
"\n",
"print(prompt_value)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "b116bb23"
},
"outputs": [],
"source": [
"llm_output = llm.invoke(prompt_value)\n",
"llm_output"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "985aa814"
},
"outputs": [],
"source": [
"output_parser.parse(llm_output)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "7b43cec2"
},
"source": [
"## Indexes\n",
"\n",
"[Indexes](https://docs.langchain.com/docs/components/indexing/) refer to ways to structure documents for LLMs to work with them.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "d3f904e9"
},
"source": [
"### **Document Loaders**\n",
"\n",
"Document loaders are ways to import data from other sources. See the [growing list](https://python.langchain.com/en/latest/modules/indexes/document_loaders.html) of document loaders here. There are more on [LlamaIndex](https://llamahub.ai/) as well that work with LangChain Document Loaders.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ee693520"
},
"outputs": [],
"source": [
"loader = WebBaseLoader(\"http://www.paulgraham.com/worked.html\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "88d89ad7"
},
"outputs": [],
"source": [
"data = loader.load()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "e814f930"
},
"outputs": [],
"source": [
"print(f\"Found {len(data)} comments\")\n",
"print(f\"Here's a sample:\\n\\n{''.join([x.page_content[:150] for x in data[:2]])}\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "0e9601db"
},
"source": [
"### **Text Splitters**\n",
"\n",
"[Text Splitters](https://python.langchain.com/docs/modules/data_connection/document_transformers/) are a way to deal with input token limits of LLMs by splitting text into chunks.\n",
"\n",
"There are many ways you could split your text into chunks, experiment with [different ones](https://python.langchain.com/docs/modules/data_connection/document_transformers/) to see which is best for your use case.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "CbA6yXonidz9"
},
"outputs": [],
"source": [
"loader = WebBaseLoader(\"http://www.paulgraham.com/worked.html\")\n",
"pg_work = loader.load()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "d19acb18"
},
"outputs": [],
"source": [
"text_splitter = RecursiveCharacterTextSplitter(\n",
" # Set a really small chunk size, just to show.\n",
" chunk_size=1000,\n",
" chunk_overlap=20,\n",
")\n",
"\n",
"texts = text_splitter.split_documents(pg_work)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "e3090f05"
},
"outputs": [],
"source": [
"print(f\"You have {len(texts)} documents\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "87a0f45a"
},
"outputs": [],
"source": [
"print(\"Preview:\")\n",
"print(texts[0].page_content, \"\\n\")\n",
"print(texts[1].page_content)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "1f85defb"
},
"source": [
"### **Retrievers**\n",
"\n",
"[Retrievers](https://python.langchain.com/docs/modules/data_connection/retrievers) are a way of storing data such that it can be queried by a language model. Easy way to combine documents with language models.\n",
"\n",
"There are [many different types of retrievers](https://python.langchain.com/docs/modules/data_connection/retrievers.html#advanced-retrieval-types), the most widely supported is the `VectorStoreRetriever`.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Vu_uBr4rKHvP"
},
"outputs": [],
"source": [
"loader = WebBaseLoader(\"http://www.paulgraham.com/worked.html\")\n",
"documents = loader.load()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "DnifR4tZkV5P"
},
"source": [
"Here we use [Facebook AI Similarity Search (FAISS)](https://engineering.fb.com/2017/03/29/data-infrastructure/faiss-a-library-for-efficient-similarity-search/), a library and a vector database for similarity search and clustering of dense vectors. To generate dense vectors, a.k.a. embeddings, we use [LangChain text embeddings model with Vertex AI Embeddings for Text](https://python.langchain.com/docs/integrations/text_embedding/google_vertex_ai_palm) .\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "1dab1c20"
},
"outputs": [],
"source": [
"# Get your splitter ready\n",
"text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=50)\n",
"\n",
"# Split your docs into texts\n",
"texts = text_splitter.split_documents(documents)\n",
"\n",
"# Embed your texts\n",
"db = FAISS.from_documents(texts, embeddings)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "e62372be"
},
"outputs": [],
"source": [
"# Init your retriever. Asking for just 1 document back\n",
"retriever = db.as_retriever()\n",
"retriever"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "3846a3b5"
},
"outputs": [],
"source": [
"docs = retriever.get_relevant_documents(\n",
" \"what types of things did the author want to develop or build?\"\n",
")\n",
"\n",
"print(\"\\n\\n\".join([x.page_content[:200] for x in docs[:2]]))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "24193139"
},
"source": [
"### Vector Stores\n",
"\n",
"[Vector Store](https://python.langchain.com/docs/modules/data_connection/vectorstores) is a common type of index or a database to store vectors (numerical embeddings). Conceptually, think of them as tables with a column for embeddings (vectors) and a column for metadata.\n",
"\n",
"Example\n",
"\n",
"| Embedding | Metadata |\n",
"| ----------------------------------------------------- | ------------------ |\n",
"| `[-0.00015641732898075134, -0.003165106289088726, ...]` | `{'date' : '1/2/23}` |\n",
"| `[-0.00035465431654651654, 1.4654131651654516546, ...]` | `{'date' : '1/3/23}` |\n",
"\n",
"- [Chroma](https://www.trychroma.com/) & [FAISS](https://engineering.fb.com/2017/03/29/data-infrastructure/faiss-a-library-for-efficient-similarity-search/) are easy to work with locally.\n",
"- [Vertex AI Vector Search (Matching Engine)](https://cloud.google.com/blog/products/ai-machine-learning/vertex-matching-engine-blazing-fast-and-massively-scalable-nearest-neighbor-search) is fully managed vector store on Google Cloud, developers can just add the embeddings to its index and issue a search query with a key embedding for the blazingly fast vector search.\n",
"\n",
"<br/>\n",
"\n",
"LangChain VectorStore is [integrated with Vertex AI Vector Search](https://python.langchain.com/v0.2/docs/integrations/vectorstores/google_vertex_ai_vector_search/)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "3c5533ad"
},
"outputs": [],
"source": [
"loader = WebBaseLoader(\"http://www.paulgraham.com/worked.html\")\n",
"documents = loader.load()\n",
"\n",
"# Get your splitter ready\n",
"text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=50)\n",
"\n",
"# Split your docs into texts\n",
"texts = text_splitter.split_documents(documents)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "661fdf19"
},
"outputs": [],
"source": [
"print(f\"You have {len(texts)} documents\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "e99ac0ea"
},
"outputs": [],
"source": [
"embedding_list = embeddings.embed_documents([text.page_content for text in texts])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "89e7758c"
},
"outputs": [],
"source": [
"print(f\"You have {len(embedding_list)} embeddings\")\n",
"print(f\"Here's a sample of one: {embedding_list[0][:3]}...\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8ac358c5"
},
"source": [
"VectorStore stores your embeddings (☝️) and makes them easily searchable.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "f9b9b79b"
},
"source": [
"## Memory\n",
"\n",
"[Memory](https://python.langchain.com/docs/modules/memory/) is the concept of storing and retrieving data in the process of a conversation. Memory helps LLMs remember information you've chatted about in the past or more complicated information retrieval.\n",
"\n",
"There are many types of memory, explore [the documentation](https://python.langchain.com/docs/modules/memory/) to see which one fits your use case.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "f43b49da"
},
"source": [
"### ConversationBufferMemory\n",
"\n",
"Memory keeps conversation state throughout a user's interactions with a language model. `ConversationBufferMemory` memory allows for storing of messages and then extracts the messages in a variable.\n",
"\n",
"We'll use `ConversationChain` to have a conversation and load context from memory. We will look into Chains in the next section.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "893a18c1"
},
"outputs": [],
"source": [
"conversation = ConversationChain(\n",
" llm=llm, verbose=True, memory=ConversationBufferMemory()\n",
")\n",
"\n",
"conversation.predict(input=\"Hi there!\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "iG0y5VXL8R6Y"
},
"outputs": [],
"source": [
"conversation.predict(input=\"What is the capital of France?\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "R7TfAEQDoPK_"
},
"outputs": [],
"source": [
"conversation.predict(input=\"What are some popular places I can see in France?\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "HoJ9HnR6oKbT"
},
"outputs": [],
"source": [
"conversation.predict(input=\"What question did I ask first?\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "f29fc79c"
},
"source": [
"## Chains ⛓️⛓️⛓️\n",
"\n",
"Chains are a generic concept in LangChain allowing to combine different LLM calls and action automatically.\n",
"\n",
"Ex:\n",
"\n",
"```\n",
"Summary #1, Summary #2, Summary #3 --> Final Summary\n",
"```\n",
"\n",
"There are [many applications of chains](https://python.langchain.com/docs/modules/chains) search to see which are best for your use case.\n",
"\n",
"We'll cover a few of them:\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "c34ba415"
},
"source": [
"### 1. Simple Sequential Chains\n",
"\n",
"[Sequential chains](https://python.langchain.com/en/latest/modules/chains/generic/sequential_chains.html) are a series of chains, called in deterministic order. `SimpleSequentialChain` are easy chains where each step uses the output of an LLM as an input into another. Good for breaking up tasks (and keeping the LLM focused).\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "43d4494a"
},
"outputs": [],
"source": [
"template = \"\"\"Your job is to come up with a classic dish from the area that the users suggests.\n",
"% USER LOCATION\n",
"{user_location}\n",
"\n",
"YOUR RESPONSE:\n",
"\"\"\"\n",
"prompt_template = PromptTemplate(input_variables=[\"user_location\"], template=template)\n",
"\n",
"# Holds my 'location' chain\n",
"location_chain = LLMChain(llm=llm, prompt=prompt_template)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "b6c8e00f"
},
"outputs": [],
"source": [
"template = \"\"\"Given a meal, give a short and simple recipe on how to make that dish at home.\n",
"% MEAL\n",
"{user_meal}\n",
"\n",
"YOUR RESPONSE:\n",
"\"\"\"\n",
"prompt_template = PromptTemplate(input_variables=[\"user_meal\"], template=template)\n",
"\n",
"# Holds my 'meal' chain\n",
"meal_chain = LLMChain(llm=llm, prompt=prompt_template)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "7e0b83f2"
},
"outputs": [],
"source": [
"overall_chain = SimpleSequentialChain(chains=[location_chain, meal_chain], verbose=True)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "7d19c64d"
},
"outputs": [],
"source": [
"review = overall_chain.invoke(\"Rome\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "f6191bf5"
},
"source": [
"### 2. Summarization Chain\n",
"\n",
"[Summarization Chain](https://python.langchain.com/docs/modules/chains/popular/summarize) easily runs through a long numerous documents and get a summary.\n",
"\n",
"There are multiple chain types such as Stuffing, Map-Reduce, Refine, Map-Rerank. Check out [documentation](https://python.langchain.com/docs/modules/chains/how_to/) for other chain types besides `map-reduce`.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "6f218c3e"
},
"outputs": [],
"source": [
"loader = WebBaseLoader(\n",
" \"https://cloud.google.com/blog/products/ai-machine-learning/how-to-use-grounding-for-your-llms-with-text-embeddings\"\n",
")\n",
"documents = loader.load()\n",
"\n",
"print(f\"# of words in the document = {len(documents[0].page_content)}\")\n",
"\n",
"# Get your splitter ready\n",
"text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=50)\n",
"\n",
"# Split your docs into texts\n",
"texts = text_splitter.split_documents(documents)\n",
"\n",
"# There is a lot of complexity hidden in this one line. I encourage you to check out the video above for more detail\n",
"chain = load_summarize_chain(llm, chain_type=\"map_reduce\", verbose=True)\n",
"chain.run(texts)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Ta-Vt4t3wTQ7"
},
"source": [
"### 3. Question/Answering Chain\n",
"\n",
"[Question Answering Chains](https://python.langchain.com/v0.1/docs/use_cases/question_answering/) easily do QA over a set of documents using QA chain. There are multiple ways to do this with LangChain. We use [**RetrievalQA** chain](https://python.langchain.com/docs/modules/chains/popular/chat_vector_db) which uses `load_qa_chain` under the hood.\n",
"\n",
"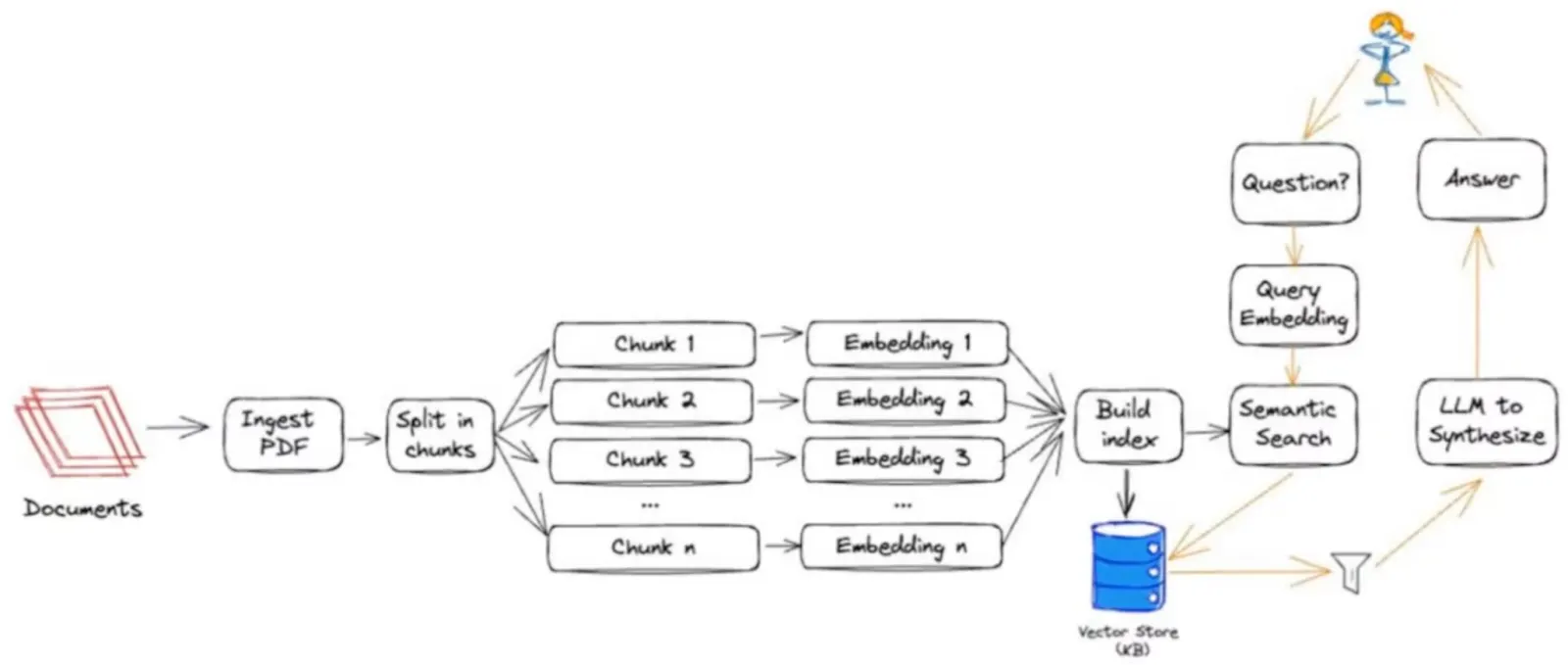"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "3QjgeWSMw0Bb"
},
"outputs": [],
"source": [
"# Load GOOG's 10K annual report (92 pages).\n",
"url = \"https://abc.xyz/assets/investor/static/pdf/20230203_alphabet_10K.pdf\"\n",
"loader = PyPDFLoader(url)\n",
"documents = loader.load()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "OJecKul0xgWT"
},
"outputs": [],
"source": [
"# split the documents into chunks\n",
"\n",
"text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=0)\n",
"docs = text_splitter.split_documents(documents)\n",
"print(f\"# of documents = {len(docs)}\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "8V8AoFiQyMSx"
},
"outputs": [],
"source": [
"# select embedding engine - we use Vertex AI Embeddings API\n",
"embeddings"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "st9_gVXmyGf6"
},
"outputs": [],
"source": [
"# Store docs in local VectorStore as index\n",
"# it may take a while since API is rate limited\n",
"db = Chroma.from_documents(docs, embeddings)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "29At6L691XZr"
},
"outputs": [],
"source": [
"# Expose index to the retriever\n",
"retriever = db.as_retriever(search_type=\"similarity\", search_kwargs={\"k\": 2})"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ibQdjXjw1foF"
},
"outputs": [],
"source": [
"# Create chain to answer questions\n",
"\n",
"# Uses LLM to synthesize results from the search index.\n",
"qa = RetrievalQA.from_chain_type(\n",
" llm=llm, chain_type=\"stuff\", retriever=retriever, return_source_documents=True\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "zvjxHX6a105H"
},
"outputs": [],
"source": [
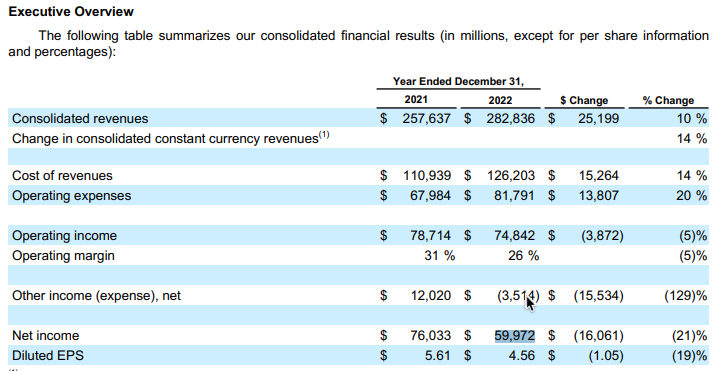
"query = \"What was Alphabet's net income in 2022?\"\n",
"result = qa.invoke({\"query\": query})\n",
"print(result)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "XLQPrNUq2aiF"
},
"source": [
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Of9XWLw9C653"
},
"outputs": [],
"source": [
"query = \"How much office space reduction took place in 2023?\"\n",
"result = qa({\"query\": query})\n",
"print(result)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Hb9RHMw5DKjQ"
},
"source": [
""
]
}
],
"metadata": {
"colab": {
"name": "intro_langchain_gemini.ipynb",
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 0
}