gemini/use-cases/retrieval-augmented-generation/NLP2SQL_using_dynamic_RAG.ipynb (1,155 lines of code) (raw):
{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "toY_CXOdqwhz"
},
"outputs": [],
"source": [
"# Copyright 2023 Google LLC\n",
"#\n",
"# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
"# you may not use this file except in compliance with the License.\n",
"# You may obtain a copy of the License at\n",
"#\n",
"# https://www.apache.org/licenses/LICENSE-2.0\n",
"#\n",
"# Unless required by applicable law or agreed to in writing, software\n",
"# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
"# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
"# See the License for the specific language governing permissions and\n",
"# limitations under the License."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_K3ySYorKlRo"
},
"source": [
"# Getting Started with NLP2SQL using dynamic RAG using\n",
"\n",
"<table align=\"left\">\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://colab.research.google.com/github/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/NLP2SQL_using_dynamic_RAG.ipynb\">\n",
" <img src=\"https://cloud.google.com/ml-engine/images/colab-logo-32px.png\" alt=\"Google Colaboratory logo\"><br> Run in Colab\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://console.cloud.google.com/vertex-ai/colab/import/https:%2F%2Fraw.githubusercontent.com%2FGoogleCloudPlatform%2Fgenerative-ai%2Fmain%2Fgemini%2Fuse-cases%2Fretrieval-augmented-generation%2FNLP2SQL_using_dynamic_RAG.ipynb\">\n",
" <img width=\"32px\" src=\"https://lh3.googleusercontent.com/JmcxdQi-qOpctIvWKgPtrzZdJJK-J3sWE1RsfjZNwshCFgE_9fULcNpuXYTilIR2hjwN\" alt=\"Google Cloud Colab Enterprise logo\"><br> Run in Colab Enterprise\n",
" </a>\n",
" </td> \n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/NLP2SQL_using_dynamic_RAG.ipynb\">\n",
" <img src=\"https://cloud.google.com/ml-engine/images/github-logo-32px.png\" alt=\"GitHub logo\"><br> View on GitHub\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://console.cloud.google.com/vertex-ai/workbench/deploy-notebook?download_url=https://raw.githubusercontent.com/GoogleCloudPlatform/generative-ai/main/gemini/use-cases/retrieval-augmented-generation/NLP2SQL_using_dynamic_RAG.ipynb\">\n",
" <img src=\"https://lh3.googleusercontent.com/UiNooY4LUgW_oTvpsNhPpQzsstV5W8F7rYgxgGBD85cWJoLmrOzhVs_ksK_vgx40SHs7jCqkTkCk=e14-rj-sc0xffffff-h130-w32\" alt=\"Vertex AI logo\"><br> Open in Vertex AI Workbench\n",
" </a>\n",
" </td>\n",
"</table>\n",
"\n",
"<div style=\"clear: both;\"></div>\n",
"\n",
"<b>Share to:</b>\n",
"\n",
"<a href=\"https://www.linkedin.com/sharing/share-offsite/?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/nlp2sql_using_dynamic_rag.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/8/81/LinkedIn_icon.svg\" alt=\"LinkedIn logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://bsky.app/intent/compose?text=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/nlp2sql_using_dynamic_rag.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/7/7a/Bluesky_Logo.svg\" alt=\"Bluesky logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://twitter.com/intent/tweet?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/nlp2sql_using_dynamic_rag.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/5/5a/X_icon_2.svg\" alt=\"X logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://reddit.com/submit?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/nlp2sql_using_dynamic_rag.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://redditinc.com/hubfs/Reddit%20Inc/Brand/Reddit_Logo.png\" alt=\"Reddit logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://www.facebook.com/sharer/sharer.php?u=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/nlp2sql_using_dynamic_rag.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/5/51/Facebook_f_logo_%282019%29.svg\" alt=\"Facebook logo\">\n",
"</a> "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "aSRSyMomGXBV"
},
"source": [
"| | |\n",
"|-|-|\n",
"|Author(s) | [Sunil Kumar Jang Bahadur](https://www.linkedin.com/in/sunilkumar88/), [Vijay Surampudi](https://www.linkedin.com/in/vijaysurampudi)|"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "l0qC59wFK5FW"
},
"source": [
"## Overview\n",
"\n",
"This notebook showcases how to utilize the \"Dynamic RAG based few shot examples\" approach to generate NLP2SQL outputs more reliably and accurately using the Vertex AI SDK for Python via the Gemini 2.0 model (`gemini-2.0-flash`).\n",
"\n",
"Gemini 2.0 model (`gemini-2.0-flash`) supports prompts with multimodal input, including natural language tasks, multi-turn text and code chat, and code generation. It can output text and code."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "QNT-6kbtMSGf"
},
"source": [
"### Objectives\n",
"\n",
"This tutorial will guide you through the process of using Dynamic RAG based Few shot examples to modify a prompt's few shot examples based on a provided input query. By utilizing the Gemini 2.0 model (`gemini-2.0-flash`) in conjunction with the Vertex AI SDK for Python, you will be able to generate SQL code or any other type of code with higher accuracy.\n",
"\n",
"You will complete the following tasks:\n",
"\n",
"- Explore the Dynamic RAG-Based Few-Shot Examples Workflow Element by Element\n",
"\n",
" Understand how each element of the Dynamic RAG-based few-shot examples workflow contributes to the overall process.\n",
"\n",
"- The Role of Multilingual Embeddings in Knowledge Transfer\n",
"\n",
" Delve into how multilingual embeddings facilitate the use of a knowledge base created in any supported language without the need for translation."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "hOvpXY-_VjTv"
},
"source": [
"### Reference architecture of Dynamic RAG based few shot examples"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "JePWTE1vN_Ex"
},
"source": [
"### Costs\n",
"This tutorial uses billable components of Google Cloud:\n",
"\n",
"- Vertex AI\n",
"\n",
"Learn about [Vertex AI pricing](https://cloud.google.com/vertex-ai/pricing) and use the [Pricing Calculator](https://cloud.google.com/products/calculator/) to generate a cost estimate based on your projected usage."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "0SbR9YTWOFki"
},
"source": [
"## Getting Started"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ByMar0B79-a1"
},
"source": [
"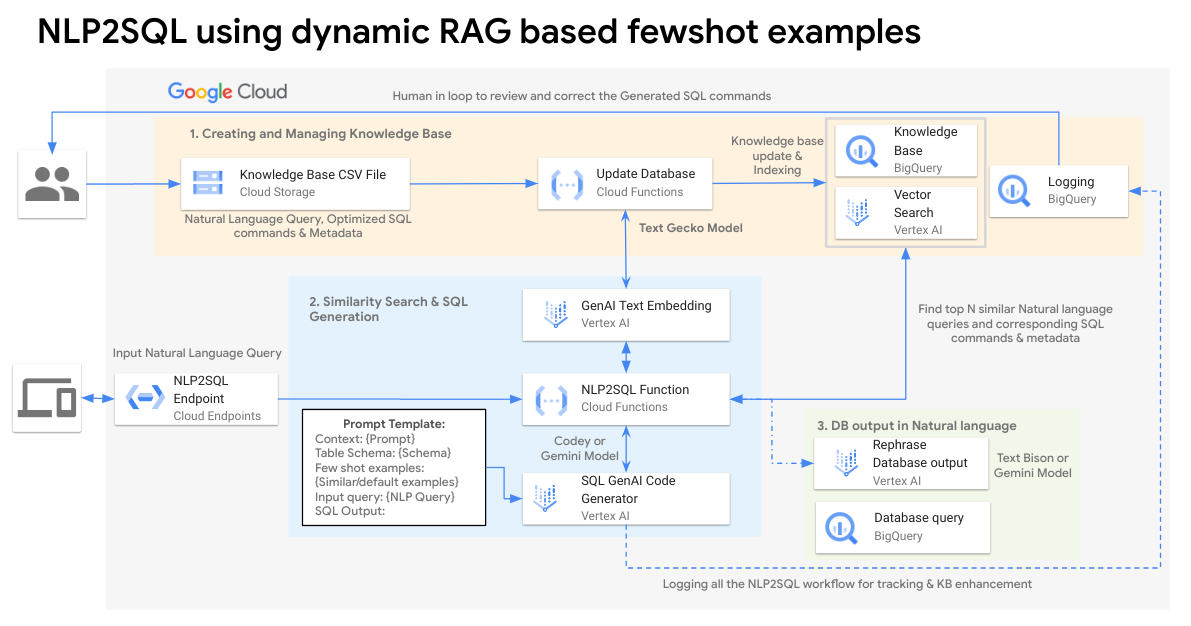"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "0Dr9jPX5Pqy1"
},
"source": [
"## Step 1: Installing the Dependencies required"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "I8QOdtTylQGt"
},
"source": [
"### Step 1.1: Install libraries"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Y73_qbbsxzMG"
},
"outputs": [],
"source": [
"# Installing dependencies\n",
"\n",
"%pip install --upgrade google-cloud-aiplatform google-cloud-storage\n",
"%pip install \"bigframes<1.0.0\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "1tE6ybI_ORyh"
},
"source": [
"### Step 1.2 Restart current runtime\n",
"\n",
"To use the newly installed packages in this Jupyter runtime, you must restart the runtime. You can do this by running the cell below, which restarts the current kernel.\n",
"\n",
"The restart might take a minute or longer. After its restarted, continue to the next step."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "MYCAHFaLOfFq"
},
"outputs": [],
"source": [
"import IPython\n",
"\n",
"app = IPython.Application.instance()\n",
"app.kernel.do_shutdown(True)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ipSMIfJuOkq8"
},
"source": [
"<div class=\"alert alert-block alert-warning\">\n",
"<b>⚠️ Wait for the kernel to finish restarting before you continue. ⚠️</b>\n",
"</div>"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "CxiCPoUzOpnn"
},
"source": [
"### Step 1.3 Authenticate your notebook environment (Colab only)\n",
"\n",
"If you are running this notebook on Google Colab, run the cell below to authenticate your environment.\n",
"\n",
"This step is not required if you are using [Vertex AI Workbench](https://cloud.google.com/vertex-ai-workbench)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "3wvpp1vJOuoF"
},
"outputs": [],
"source": [
"import sys\n",
"\n",
"# Additional authentication is required for Google Colab\n",
"if \"google.colab\" in sys.modules:\n",
" # Authenticate user to Google Cloud\n",
" from google.colab import auth\n",
"\n",
" auth.authenticate_user()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "fNGLmcx5Oz0l"
},
"source": [
"### Step 1.4 Define Google Cloud project information and initialize Vertex AI\n",
"\n",
"Initialize the Vertex AI SDK for Python for your project:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "xXhn9fpVO2da"
},
"outputs": [],
"source": [
"# Define project information\n",
"PROJECT_ID = \"PROJECT_ID\" # @param {type:\"string\"}\n",
"LOCATION = \"LOCATION\" # @param {type:\"string\"}\n",
"BATCH_SIZE = 5\n",
"\n",
"# Initialize Vertex AI\n",
"import vertexai\n",
"\n",
"vertexai.init(project=PROJECT_ID, location=LOCATION)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8Ir3uY0PO94I"
},
"source": [
"### Step 1.5 Import libraries"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "2iiIFKUbPGmm"
},
"outputs": [],
"source": [
"from datetime import datetime\n",
"import time\n",
"\n",
"import numpy as np\n",
"import pandas as pd\n",
"import tqdm # to show a progress bar\n",
"from vertexai.generative_models import GenerativeModel\n",
"from vertexai.language_models import CodeGenerationModel, TextEmbeddingModel"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "RoXD-s6lQMjh"
},
"source": [
"### Step 2: Indexing the Knowledge Base"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "jAjMFYLtlyQ6"
},
"source": [
"### Step 2.1 Load the Gemini, Codey & Text Embedding model\n",
"\n",
"[List of languages supported in Multilingual embedding model](https://cloud.google.com/vertex-ai/generative-ai/docs/embeddings/get-text-embeddings#language_coverage_for_text-embedding-005-multilingual_models)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "bjd9_UZqyi_m"
},
"outputs": [],
"source": [
"# Load the code & text embeddings model\n",
"embedding_model = TextEmbeddingModel.from_pretrained(\n",
" \"text-embedding-005-multilingual@001\"\n",
")\n",
"gemini_model = GenerativeModel(\"gemini-2.0-flash\")\n",
"code_model = CodeGenerationModel.from_pretrained(\"code-bison\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "HyLEjxzJlJQG"
},
"source": [
"### Step 2.2 Knowledge base CSV to DataFrame. This could be a database as well, but lets consider CSV for now.\n",
"Upload the CSV file from the GitHub to Colab"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "vfRKebcsyIM1"
},
"outputs": [],
"source": [
"# Reading the CSV file containing Knowledge Base of sample queries\n",
"df = pd.read_csv(\"queries_sample_knowledge_base.csv\")\n",
"\n",
"print(df.to_string())"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_NI6hWKal7Rw"
},
"source": [
"### Step 2.3 Retrieve Embeddings using APIs for given text"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "5g0nr7QHyzFc"
},
"outputs": [],
"source": [
"def get_embeddings_wrapper(texts):\n",
" \"\"\"\n",
" This function retrieves embeddings for a list of texts using the provided embedding model,\n",
" handling batching and rate limiting to avoid exceeding API quotas.\n",
"\n",
" Args:\n",
" texts (list): A list of text strings.\n",
"\n",
" Returns:\n",
" list: A list of embedding vectors for each text in the input list.\n",
" \"\"\"\n",
"\n",
" embs = []\n",
" for i in tqdm.tqdm(range(0, len(texts), BATCH_SIZE)):\n",
" # Sleep for 1 second to avoid exceeding API quotas.\n",
" time.sleep(1)\n",
"\n",
" # Get embeddings for the current batch of texts.\n",
" result = embedding_model.get_embeddings(texts[i : i + BATCH_SIZE])\n",
"\n",
" # Extract and append the embedding vectors to the list.\n",
" embs = embs + [e.values for e in result]\n",
"\n",
" return embs"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "xNpENdz6Xj5W"
},
"source": [
"### Step 2.4 Generate embedding of all the natural language queries"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "c6eOUISmy_Zg"
},
"outputs": [],
"source": [
"# Get embeddings for the questions and assign them to a new column.\n",
"df = df.assign(embedding=get_embeddings_wrapper(list(df.question)))\n",
"df.head()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "JAD3OJIRmBJ6"
},
"source": [
"### Step 2.5 Create JSON file to be used for Vector Store"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "LQCZOMhJzQ6D"
},
"outputs": [],
"source": [
"# save id and embedding as a json file\n",
"jsonl_string = df[[\"id\", \"embedding\"]].to_json(orient=\"records\", lines=True)\n",
"with open(\"questions.json\", \"w\") as f:\n",
" f.write(jsonl_string)\n",
"\n",
"# show the first few lines of the json file\n",
"! head -n 3 questions.json"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "YOzXehrGnfU_"
},
"source": [
"### Local Similarity Search Test Run using only DataFrame"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "214vdoNNzcR3"
},
"outputs": [],
"source": [
"text_query = (\n",
" \"Can i get transaction details done in offshore currency\" # @param {type:\"string\"}\n",
")\n",
"test_embeddings = get_embeddings_wrapper([text_query])\n",
"print(test_embeddings)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Fot69VLm20Hh"
},
"outputs": [],
"source": [
"# Convert the embeddings column of the DataFrame to a numpy array.\n",
"embs = np.array(df.embedding.to_list())\n",
"\n",
"# Calculate the similarity scores between the text query and each question.\n",
"similarities = np.dot(test_embeddings[0], embs.T)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "3nHPuR3E4Wel"
},
"outputs": [],
"source": [
"print(similarities)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "4OCzGEf_3vRf"
},
"outputs": [],
"source": [
"# print the question\n",
"print(\"Key question: Can i get transaction details done in offshore currency\")\n",
"\n",
"# sort and print the questions by similarities\n",
"sorted_questions = sorted(\n",
" zip(df.question, similarities, df.query_1), key=lambda x: x[1], reverse=True\n",
")[:10]\n",
"\n",
"for i, (question, similarity, query_1) in enumerate(sorted_questions):\n",
" print(f\"\\n \\n Similarity: {similarity}: {question}\")\n",
" print(f\"SQL Query: {query_1}\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "28gYiM7S76c4"
},
"outputs": [],
"source": [
"def find_similar_questions(df, text_query):\n",
" \"\"\"\n",
" This function finds the most similar questions to a given text query.\n",
"\n",
" Args:\n",
" df (pd.DataFrame): A DataFrame containing question-answer pairs.\n",
" The DataFrame should have the following columns:\n",
" - question: The question text.\n",
" - query_1: The query text.\n",
" - embedding: The embedding vector of the question.\n",
" text_query (str): The text query to compare against.\n",
"\n",
" Returns:\n",
" list: A list of the 10 most similar questions and their similarity scores.\n",
" \"\"\"\n",
"\n",
" # Get the embedding vector of the text query.\n",
" test_embeddings = get_embeddings_wrapper([text_query])\n",
"\n",
" # Convert the embeddings column of the DataFrame to a numpy array.\n",
" embs = np.array(df.embedding.to_list())\n",
"\n",
" # Calculate the similarity scores between the text query and each question.\n",
" similarities = np.dot(test_embeddings[0], embs.T)\n",
"\n",
" # Sort the questions by similarity score and return the top 10.\n",
" sorted_questions = sorted(\n",
" zip(df.question, similarities, df.query_1), key=lambda x: x[1], reverse=True\n",
" )[:10]\n",
"\n",
" # Print the top 10 questions and their similarity scores.\n",
" for i, (question, similarity, query_1) in enumerate(sorted_questions):\n",
" print(f\"\\n \\n Similarity: {similarity}: {question}\")\n",
" print(f\"SQL Query: {query_1}\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "B4jJ6FHM8S1D"
},
"outputs": [],
"source": [
"text_query = (\n",
" \"Can i get transaction details done in offshore currency\" # @param {type:\"string\"}\n",
")\n",
"find_similar_questions(df, text_query)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ie4suIRSnuZ6"
},
"source": [
"### Multi-lingual Test Run"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "iWyfeyCf8qOd"
},
"outputs": [],
"source": [
"text_query = (\n",
" \"展示Foreign Currency Transactions 2023年10月的信息\" # @param {type:\"string\"}\n",
")\n",
"find_similar_questions(df, text_query)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_L0-rsUWnz30"
},
"source": [
"### GCloud login to setup Vector Store on Google Cloud"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Gf5f6_PnPqD0"
},
"outputs": [],
"source": [
"!gcloud auth login"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "48J0qv2XQDRX"
},
"outputs": [],
"source": [
"!gcloud config set project \"{PROJECT_ID}\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "OUoTxFhHM_sL"
},
"outputs": [],
"source": [
"UID = datetime.now().strftime(\"%m%d%H%M\")\n",
"BUCKET_URI = f\"gs://{PROJECT_ID}-embvs-tutorial-{UID}\"\n",
"! gsutil mb -l $LOCATION -p {PROJECT_ID} {BUCKET_URI}\n",
"! gsutil cp questions.json {BUCKET_URI}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "eesHfpfNQiC7"
},
"outputs": [],
"source": [
"# init the aiplatform package\n",
"from google.cloud import aiplatform\n",
"\n",
"aiplatform.init(project=PROJECT_ID, location=LOCATION)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "PuwrEocPQmYp"
},
"outputs": [],
"source": [
"# create index\n",
"my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(\n",
" display_name=f\"embvs-tutorial-index-{UID}\",\n",
" contents_delta_uri=BUCKET_URI,\n",
" dimensions=768,\n",
" approximate_neighbors_count=20,\n",
" distance_measure_type=\"DOT_PRODUCT_DISTANCE\",\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "kMP3UUSeRD5l"
},
"outputs": [],
"source": [
"# create IndexEndpoint\n",
"my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(\n",
" display_name=f\"embvs-tutorial-index-endpoint-{UID}\",\n",
" public_endpoint_enabled=True,\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "MXRzaQpFRF6Q"
},
"outputs": [],
"source": [
"# deploy the Index to the Index Endpoint\n",
"DEPLOYED_INDEX_ID = f\"embvs_tutorial_deployed_{UID}\"\n",
"my_index_endpoint.deploy_index(index=my_index, deployed_index_id=DEPLOYED_INDEX_ID)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Ufrn4cNCn-f4"
},
"source": [
"### Local Test Run using Vector Store"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "-2Ky0FWFRhCQ"
},
"outputs": [],
"source": [
"text_query = (\n",
" \"Can i get transaction details done in offshore currency\" # @param {type:\"string\"}\n",
")\n",
"test_embeddings = get_embeddings_wrapper([text_query])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "cNcSzza7RPLt"
},
"outputs": [],
"source": [
"# Test query\n",
"response = my_index_endpoint.find_neighbors(\n",
" deployed_index_id=DEPLOYED_INDEX_ID,\n",
" queries=test_embeddings,\n",
" num_neighbors=5,\n",
")\n",
"\n",
"# show the result\n",
"for idx, neighbor in enumerate(response[0]):\n",
" id = np.int64(neighbor.id)\n",
" similar = df.query(\"id == @id\", engine=\"python\")\n",
" print(id, neighbor.distance)\n",
" print(str(similar.question.values[0]))\n",
" print(str(similar.query_1.values[0]))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "uWBpLFQsoG6n"
},
"source": [
"### Fetch the Vector Store Endpoint using ID"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Fn_NPCEoRi8O"
},
"outputs": [],
"source": [
"my_deployed_index_id = \"DEPLOYED_INDEX_ID\" # @param {type:\"string\"}\n",
"my_current_index_endpoint_id = \"INDEX_ENDPOINT_ID\" # @param {type:\"string\"}\n",
"my_current_index_endpoint_id = aiplatform.MatchingEngineIndexEndpoint(\n",
" my_current_index_endpoint_id\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Hy9VMxX-oUbq"
},
"source": [
"### Similarity Search using Endpoint in Few Shot example template"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ncnIpJpBSDv8"
},
"outputs": [],
"source": [
"def get_similar_entries(text_query):\n",
" \"\"\"\n",
" Finds the most similar entries in a deployed index for a given text query.\n",
"\n",
" Args:\n",
" text_query (str): The text query to search for similar entries.\n",
"\n",
" Returns:\n",
" str: A formatted string containing information about the most similar entry.\n",
" \"\"\"\n",
"\n",
" # Get the embedding for the text query.\n",
" test_embeddings = get_embeddings_wrapper([text_query])\n",
"\n",
" # Find similar entries in the deployed index.\n",
" response = my_current_index_endpoint_id.find_neighbors(\n",
" deployed_index_id=my_deployed_index_id,\n",
" queries=test_embeddings,\n",
" num_neighbors=1,\n",
" )\n",
"\n",
" # Initialize a string to store the result.\n",
" similar_examples = \"\"\n",
"\n",
" # Iterate through the nearest neighbors and extract relevant information.\n",
" for idx, neighbor in enumerate(response[0]):\n",
" id = np.int64(neighbor.id)\n",
" print(id, neighbor.distance)\n",
" similar = df.query(\"id == @id\", engine=\"python\")\n",
" similar_examples += f\"INPUT:{similar.question.values[0]}\\n RESPONSE:{similar.query_1.values[0]}\\n\"\n",
"\n",
" return similar_examples"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "8HnH-WA9T0Uz"
},
"outputs": [],
"source": [
"similar_query = get_similar_entries(text_query)\n",
"print(similar_query)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "BJt7_GsOoZGt"
},
"source": [
"### Codey to Generate the SQL command using Few shot examples"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "iZngIC3sj2h2"
},
"outputs": [],
"source": [
"code_parameters = {\"candidate_count\": 1, \"max_output_tokens\": 1024, \"temperature\": 0.0}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "xCsflOR1jkUp"
},
"outputs": [],
"source": [
"table = \"\"\"CREATE TABLE transactions (\n",
" Cust_ID VARCHAR(255),\n",
" Date DATE,\n",
" Time TIME,\n",
" Transaction_Description VARCHAR(255),\n",
" Value FLOAT,\n",
" Fuel VARCHAR(255),\n",
" Foreign_Currency VARCHAR(255),\n",
" Smartbuy VARCHAR(255),\n",
" Points_Accrued FLOAT\n",
")\n",
"\"\"\"\n",
"\n",
"response = code_model.predict(\n",
" prefix=f\"\"\"Write a SQL Query based on given schema details for the given question and context.\n",
" Response should be as per output template.\n",
"CONTEXT:\n",
"{table}\n",
"EXAMPLES: {similar_query}\n",
"INPUT:{text_query}\n",
"OUTPUT:```sql```\"\"\",\n",
" **code_parameters,\n",
")\n",
"print(f\"Response from Model: \\n {response.text}\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "omwkm1UrYqAK"
},
"source": [
"### Gemini 2.0 to Generate the SQL command using Few shot examples"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Fnun00WXXcDM"
},
"outputs": [],
"source": [
"responses = gemini_model.generate_content(\n",
" f\"\"\"Write a SQL Query based on given schema details for the given question and context.\n",
"Response should be as per output template.\n",
" CONTEXT:\n",
" {table}\n",
" EXAMPLES: {similar_query}\n",
" INPUT:{text_query}\n",
" OUTPUT:```sql```\"\"\",\n",
" generation_config={\"max_output_tokens\": 2048, \"temperature\": 0.0, \"top_p\": 1},\n",
" stream=False,\n",
")\n",
"print(responses.text)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "wNh5fCjjLi5o"
},
"source": [
"### Codey to Generate the SQL command by leveraging OOTB multilingual support in the model"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "tDoTnpp72mFR"
},
"outputs": [],
"source": [
"text_query_test = \"\\u0986\\u09ae\\u09bf \\u0995\\u09bf \\u0985\\u09ab\\u09b6\\u09cb\\u09b0 \\u0995\\u09be\\u09b0\\u09c7\\u09a8\\u09cd\\u09b8\\u09bf\\u09a4\\u09c7 \\u09b2\\u09c7\\u09a8\\u09a6\\u09c7\\u09a8\\u09c7\\u09b0 \\u09ac\\u09bf\\u09ac\\u09b0\\u09a3 \\u09aa\\u09c7\\u09a4\\u09c7 \\u09aa\\u09be\\u09b0\\u09bf?\" # @param {type:\"string\"}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "44S8ZP1-p3hy"
},
"outputs": [],
"source": [
"similar_query_response = get_similar_entries(text_query_test)\n",
"print(similar_query_response)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "PMSSE6YzjkKr"
},
"outputs": [],
"source": [
"table = \"\"\"CREATE TABLE transactions (\n",
" Cust_ID VARCHAR(255),\n",
" Date DATE,\n",
" Time TIME,\n",
" Transaction_Description VARCHAR(255),\n",
" Value FLOAT,\n",
" Fuel VARCHAR(255),\n",
" Foreign_Currency VARCHAR(255),\n",
" Smartbuy VARCHAR(255),\n",
" Points_Accrued FLOAT\n",
")\n",
"\"\"\"\n",
"# Output response is requested in english to avoid and localized content generation in SQL\n",
"# Since current DB used just have entries in English locale\n",
"response = code_model.predict(\n",
" prefix=f\"\"\"Write a SQL Query based on given schema details for the given question and context in English only.\n",
" Response should be as per output template.\n",
"CONTEXT:\n",
"{table}\n",
"EXAMPLES: {similar_query}\n",
"INPUT:{text_query_test}\n",
"OUTPUT:```sql```\"\"\",\n",
" **code_parameters,\n",
")\n",
"print(f\"Response from Model: \\n {response.text}\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "kUOD4g_LYjvb"
},
"source": [
"### Gemini 2.0 to Generate the SQL command by leveraging OOTB multilingual support in the model"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ew0301-fYUBW"
},
"outputs": [],
"source": [
"responses = gemini_model.generate_content(\n",
" f\"\"\"Write a SQL Query based on given schema details for the given question and context in English only. Response should be as per output template.\n",
" CONTEXT:\n",
" {table}\n",
" EXAMPLES: {similar_query}\n",
" INPUT:{text_query_test}\n",
" OUTPUT:```sql```\"\"\",\n",
" generation_config={\"max_output_tokens\": 2048, \"temperature\": 0.0, \"top_p\": 1},\n",
" stream=False,\n",
")\n",
"print(responses.text)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "HVipE1jo6ZES"
},
"source": [
"### NLP to SQL using Codey without any Few shot examples"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "pUarHIiy5vUA"
},
"outputs": [],
"source": [
"# Output response is requested in english to avoid and localized content generation in SQL\n",
"# Since current DB used just have entries in English locale\n",
"response = code_model.predict(\n",
" prefix=f\"\"\"Write a SQL Query based on given schema details for the given question and context in English.\n",
" Response should be as per output template.\n",
"CONTEXT:\n",
"{table}\n",
"INPUT:{text_query_test}\n",
"OUTPUT:```sql```\"\"\",\n",
" **code_parameters,\n",
")\n",
"print(f\"Response from Model: \\n {response.text}\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ecEvsFc-ZB4u"
},
"source": [
"### NLP to SQL using Gemini 2.0 without any Few shot examples"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "bwefMLuCY1Xk"
},
"outputs": [],
"source": [
"responses = gemini_model.generate_content(\n",
" f\"\"\"Write a SQL Query based on given schema details for the given question and context.\n",
"Response should be as per output template.\n",
" CONTEXT:\n",
" {table}\n",
" INPUT:{text_query_test}\n",
" OUTPUT:```sql```\"\"\",\n",
" generation_config={\"max_output_tokens\": 2048, \"temperature\": 0.0, \"top_p\": 1},\n",
" stream=False,\n",
")\n",
"print(responses.text)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "F8eL0uGzohrA"
},
"source": [
"### Delete the Setup (Uncomment before executing)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "qeBGI5vvSVaB"
},
"outputs": [],
"source": [
"# wait for a confirmation\n",
"# input(\"Press Enter to delete Index Endpoint, Index and Cloud Storage bucket:\")\n",
"\n",
"# delete Index Endpoint\n",
"# my_index_endpoint.undeploy_all()\n",
"# my_index_endpoint.delete(force = True)\n",
"\n",
"# delete Index\n",
"# my_index.delete()\n",
"\n",
"# delete Cloud Storage bucket\n",
"# ! gsutil rm -r {BUCKET_URI}"
]
}
],
"metadata": {
"colab": {
"name": "NLP2SQL_using_dynamic_RAG.ipynb",
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 0
}