gemini/use-cases/retrieval-augmented-generation/intra_knowledge_qna.ipynb (771 lines of code) (raw):
{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "iyi0u1inBcr1"
},
"outputs": [],
"source": [
"# Copyright 2024 Google LLC\n",
"#\n",
"# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
"# you may not use this file except in compliance with the License.\n",
"# You may obtain a copy of the License at\n",
"#\n",
"# https://www.apache.org/licenses/LICENSE-2.0\n",
"#\n",
"# Unless required by applicable law or agreed to in writing, software\n",
"# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
"# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
"# See the License for the specific language governing permissions and\n",
"# limitations under the License."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "BLIlkXRfCNyQ"
},
"source": [
"# Intra Knowledge QnA\n",
"\n",
"<table align=\"left\">\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://colab.research.google.com/github/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/intra_knowledge_qna.ipynb\">\n",
" <img src=\"https://cloud.google.com/ml-engine/images/colab-logo-32px.png\" alt=\"Google Colaboratory logo\"><br> Open in Colab\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://console.cloud.google.com/vertex-ai/colab/import/https:%2F%2Fraw.githubusercontent.com%2FGoogleCloudPlatform%2Fgenerative-ai%2Fmain%2Fgemini%2Fuse-cases%2Fretrieval-augmented-generation%2Fintra_knowledge_qna.ipynb\">\n",
" <img width=\"32px\" src=\"https://lh3.googleusercontent.com/JmcxdQi-qOpctIvWKgPtrzZdJJK-J3sWE1RsfjZNwshCFgE_9fULcNpuXYTilIR2hjwN\" alt=\"Google Cloud Colab Enterprise logo\"><br> Open in Colab Enterprise\n",
" </a>\n",
" </td> \n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://console.cloud.google.com/vertex-ai/workbench/deploy-notebook?download_url=https://raw.githubusercontent.com/GoogleCloudPlatform/generative-ai/main/gemini/use-cases/retrieval-augmented-generation/intra_knowledge_qna.ipynb\">\n",
" <img src=\"https://lh3.googleusercontent.com/UiNooY4LUgW_oTvpsNhPpQzsstV5W8F7rYgxgGBD85cWJoLmrOzhVs_ksK_vgx40SHs7jCqkTkCk=e14-rj-sc0xffffff-h130-w32\" alt=\"Vertex AI logo\"><br> Open in Workbench\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/intra_knowledge_qna.ipynb\">\n",
" <img src=\"https://cloud.google.com/ml-engine/images/github-logo-32px.png\" alt=\"GitHub logo\"><br> View on GitHub\n",
" </a>\n",
" </td>\n",
"</table>\n",
"\n",
"<div style=\"clear: both;\"></div>\n",
"\n",
"<b>Share to:</b>\n",
"\n",
"<a href=\"https://www.linkedin.com/sharing/share-offsite/?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/intra_knowledge_qna.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/8/81/LinkedIn_icon.svg\" alt=\"LinkedIn logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://bsky.app/intent/compose?text=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/intra_knowledge_qna.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/7/7a/Bluesky_Logo.svg\" alt=\"Bluesky logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://twitter.com/intent/tweet?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/intra_knowledge_qna.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/5/5a/X_icon_2.svg\" alt=\"X logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://reddit.com/submit?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/intra_knowledge_qna.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://redditinc.com/hubfs/Reddit%20Inc/Brand/Reddit_Logo.png\" alt=\"Reddit logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://www.facebook.com/sharer/sharer.php?u=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/intra_knowledge_qna.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/5/51/Facebook_f_logo_%282019%29.svg\" alt=\"Facebook logo\">\n",
"</a> "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "WBpYfJP8Ce4s"
},
"source": [
"| | |\n",
"|--------------------------------------------|---------------------------------------------------------|\n",
"|Author(s) | |\n",
"|[Tanya Warrier](https://github.com/tanyarw) |[Samriddhi Mishra](https://github.com/samriddhimishra07) |\n",
"|[Neelay Shah](https://github.com/neelay21) | [Kumar Saurabh](https://github.com/kusaurabh24) |"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "WZPabwVQCh1y"
},
"source": [
"## Overview\n",
"\n",
"- **Gemini:** [Gemini](https://ai.google.dev/models/gemini) is a family of generative AI models that lets developers generate content and solve problems. These models are designed and trained to handle both text and images as input.\n",
" - **Gemini 2.0 model (gemini-2.0-flash):** Designed to handle multimodal inputs, including multi-turn text and code chat, and code generation.\n",
"\n",
"- **LangChain:** [LangChain](https://www.langchain.com/) is a framework designed to make integration of Large Language Models (LLM) like Gemini easier for applications.\n",
"\n",
"- **Chroma DB:** [Chroma](https://python.langchain.com/docs/integrations/vectorstores/chroma) is the open-source embedding database. Chroma makes it easy to build LLM apps by making knowledge, facts, and skills pluggable for LLMs.\n",
"\n",
"- **Vertex AI Embeddings for Text:** With [text-embedding-005](https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/text-embeddings) models we can easily create a text embedding with LLM. *text-embedding-005* is the newest stable embedding model.\n",
"\n",
"\n",
"For more information, see the [Generative AI](https://cloud.google.com/vertex-ai/docs/generative-ai/learn/overview) on Vertex AI documentation.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ZPJulXlX0oSd"
},
"source": [
"### Objectives\n",
"\n",
"This notebook leverages Google Vertex AI's Generative capabilities to parse multiple PDF documents, offering Question & Answering functionality by cross-referencing the provided documents. Additionally, it assists in identification of relevant answer sections within the provided documents.\n",
"\n",
"This notebook uses [LangChain](https://python.langchain.com/docs/get_started/introduction.html) to operationalize workflows for Question & Answer capabilities, and it utilizes [Chroma DB](https://python.langchain.com/docs/integrations/vectorstores/chroma) to persist document embeddings for similarity searches.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "K6-K0sBh4Ape"
},
"source": [
"### Architecture outlining the workflow approach"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "0zvl1NbGDKdR"
},
"source": [
"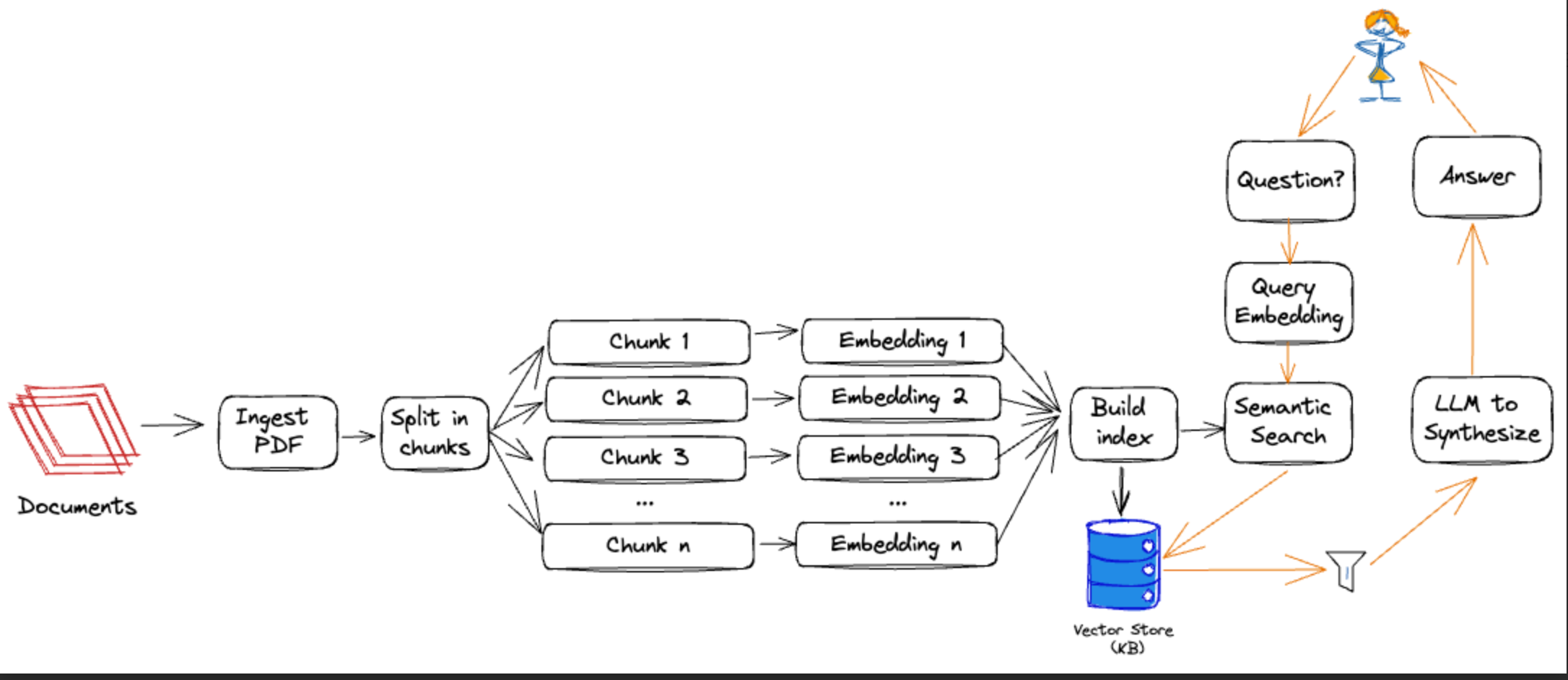"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "fdU7KNcCCkOA"
},
"source": [
"## Getting Started\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "6XczCHZYCmi1"
},
"source": [
"### Install Vertex AI SDK and other required packages\n",
"\n",
"Install LangChain's Python library, `langchain`, LangChain's integration package for Google Vertex AI, `langchain_google_vertexai`, Chroma for persisting embeddings, `chromadb` and other required packages."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "nzZqdQN4_GDz"
},
"outputs": [],
"source": [
"!apt-get install poppler-utils \\\n",
"tesseract-ocr -y\n",
"\n",
"%pip install google-cloud-aiplatform==1.46.0 \\\n",
"'bigframes<1.0.0' \\\n",
"langchain==0.1.14 \\\n",
"langchain_google_vertexai==0.1.2 \\\n",
"chromadb==0.4.24 \\\n",
"unstructured==0.12.6 \\\n",
"pillow-heif==0.15.0 \\\n",
"unstructured-inference==0.7.25 \\\n",
"pypdf==4.1.0 \\\n",
"pdf2image==1.17.0 \\\n",
"unstructured_pytesseract==0.3.12 \\\n",
"pikepdf==8.14.0 \\\n",
"--upgrade \\\n",
"--user --quiet"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "bHV6vh55Cqln"
},
"source": [
"### Restart runtime (Colab only)\n",
"\n",
"To use the newly installed packages in this Jupyter runtime, you must restart the runtime. You can do this by running the cell below, which will restart the current kernel."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "mB85g9FpDu0e"
},
"outputs": [],
"source": [
"import sys\n",
"\n",
"if \"google.colab\" in sys.modules:\n",
" import IPython\n",
"\n",
" app = IPython.Application.instance()\n",
" app.kernel.do_shutdown(True)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "WcesVUMO6sDg"
},
"source": [
"<div class=\"alert alert-block alert-warning\">\n",
"<b>⚠️ The kernel is going to restart. Please wait until it is finished before continuing to the next step. ⚠️</b>\n",
"</div>"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "K810s6DICwe1"
},
"source": [
"### Authenticate your notebook environment (Colab only)\n",
"\n",
"\n",
"If you are running this notebook on Google Colab, run the following cell to authenticate your environment."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "K0xFZPSpDcog"
},
"outputs": [],
"source": [
"import sys\n",
"\n",
"if \"google.colab\" in sys.modules:\n",
" from google.colab import auth\n",
"\n",
" auth.authenticate_user()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "xyDpSIRWC0g2"
},
"source": [
"### Set Google Cloud project information and initialize Vertex AI SDK\n",
"\n",
"To get started using Vertex AI, you must have an existing Google Cloud project and [enable the Vertex AI API](https://console.cloud.google.com/flows/enableapi?apiid=aiplatform.googleapis.com).\n",
"\n",
"Learn more about [setting up a project and a development environment](https://cloud.google.com/vertex-ai/docs/start/cloud-environment)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "mv3ho2AwDkID"
},
"outputs": [],
"source": [
"PROJECT_ID = \"your-project-id\" # @param {type:\"string\"}\n",
"LOCATION = \"us-central1\" # @param {type:\"string\"}\n",
"\n",
"import vertexai\n",
"\n",
"vertexai.init(project=PROJECT_ID, location=LOCATION)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "z2IAV3YtEFQ4"
},
"source": [
"### Variables\n",
"\n",
"Create variables to store the folder location of all the pdf documents needed to be indexed. Also, the location to store the embedding database for the documents."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "c-cbO2o9F0Yx"
},
"outputs": [],
"source": [
"INDEX_PATH = \"./Dataset/\"\n",
"PERSIST_PATH = \"./PersistentDB/\"\n",
"\n",
"MULTIMODAL_MODEL = \"gemini-2.0-flash\"\n",
"EMBEDDING_MODEL = \"text-embedding-005\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ooauhzOWPvC1"
},
"source": [
"### Import Libraries\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Hj6K6SFIEnRk"
},
"outputs": [],
"source": [
"# Utils\n",
"import os\n",
"\n",
"# LangChain\n",
"import langchain\n",
"from langchain.chains import create_retrieval_chain\n",
"from langchain.chains.combine_documents import create_stuff_documents_chain\n",
"from langchain.document_loaders import TextLoader, UnstructuredPDFLoader\n",
"from langchain.prompts import PromptTemplate\n",
"from langchain.text_splitter import CharacterTextSplitter\n",
"from langchain.vectorstores.chroma import Chroma\n",
"from langchain_google_vertexai import VertexAI, VertexAIEmbeddings\n",
"\n",
"print(f\"LangChain version: {langchain.__version__}\")\n",
"\n",
"# Vertex AI\n",
"from google.cloud import aiplatform\n",
"\n",
"print(f\"Vertex AI SDK version: {aiplatform.__version__}\")\n",
"\n",
"from IPython.display import clear_output\n",
"\n",
"# HTML Widgets\n",
"import ipywidgets as widgets"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_D5yf9ILC3ZM"
},
"source": [
"### Data Preparation\n",
"\n",
"We will be using the public [Internal Revenue Service(IRS) document](https://www.irs.gov/pub/irs-pdf/p554.pdf) which states the details for each section of tax eligibility for seniors in the USA. It consists of 37 pages.\n",
"\n",
"This document serves as the input PDF for generating and indexing embeddings, querying the model, and facilitating Question and Answer scenarios based on the data corpus."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "QyFyNdqvD08b"
},
"outputs": [],
"source": [
"# Create the folder for input files\n",
"!mkdir -p $INDEX_PATH\n",
"\n",
"# Download the files\n",
"!wget https://www.irs.gov/pub/irs-pdf/p554.pdf -P $INDEX_PATH"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "hy1MspayJCaO"
},
"source": [
"### Define utility functions"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "hul0HgRpUVCC"
},
"source": [
"**Document Loading:** Read in the content of the documents from the provided directory.\n",
"\n",
"**Document Splitting:**\n",
"Creates a CharacterTextSplitter object with parameters:\n",
"- `chunk_size=8192`: Aiming for text chunks of around 8192 characters.\n",
"- `chunk_overlap=128:` A small overlap between chunks, likely to preserve context when documents are split.\n",
"\n",
"Applies the *text_splitter* to the loaded documents, breaking them into smaller, more manageable text chunks.\n",
"\n",
"Gathers all the split text chunks into a single list and return for further processing."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "l3RcBOL3T544"
},
"outputs": [],
"source": [
"def get_split_documents(index_path: str) -> list[str]:\n",
" \"\"\"\n",
" This function is used to chunk documents and convert them into a list.\n",
"\n",
" Args:\n",
" index_path: Path of the dataset folder containing the documents.\n",
"\n",
" Returns:\n",
" List of chunked, or split documents.\n",
" \"\"\"\n",
"\n",
" split_docs = []\n",
"\n",
" for file_name in os.listdir(index_path):\n",
" print(f\"file_name : {file_name}\")\n",
" if file_name.endswith(\".pdf\"):\n",
" loader = UnstructuredPDFLoader(index_path + file_name)\n",
" else:\n",
" loader = TextLoader(index_path + file_name)\n",
"\n",
" text_splitter = CharacterTextSplitter(chunk_size=8192, chunk_overlap=128)\n",
" split_docs.extend(text_splitter.split_documents(loader.load()))\n",
"\n",
" return split_docs"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "QLZZqHlbS1QS"
},
"source": [
"### Create Vector Database\n",
"\n",
"Instantiate a VertexAIEmbeddings embedding object that will efficiently generate text embeddings using the specified `text-embedding-005` model."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Zgf_ZbKAFuIr"
},
"outputs": [],
"source": [
"# Custom Vertex AI Embeddings object\n",
"EMBEDDING_NUM_BATCH = 5\n",
"\n",
"embeddings = VertexAIEmbeddings(\n",
" model_name=EMBEDDING_MODEL, batch_size=EMBEDDING_NUM_BATCH\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "U7hZWC6_X26R"
},
"source": [
"**Load Documents:** `get_split_documents` function retrieves and preprocesses documents from the specified `INDEX_PATH`.\n",
"\n",
"**Generate Embeddings:** The code generates vector embeddings\n",
"\n",
"**Create Vector Database:** A Chroma vector database (db) is initialized. This specialized database is designed for storing and efficiently searching vector embeddings.\n",
"\n",
"**Persist Database:** The `db.persist()` command saves the newly created vector database to disk at the location defined by `PERSIST_PATH` environment variable."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "CvvVjL2pGzCB"
},
"outputs": [],
"source": [
"# Load documents, generate vectors and store in Vector database\n",
"split_docs = get_split_documents(INDEX_PATH)\n",
"\n",
"db = Chroma.from_documents(\n",
" documents=split_docs, embedding=embeddings, persist_directory=PERSIST_PATH\n",
")\n",
"db.persist() # Ensure DB persist"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "9nqDSy0QYsgC"
},
"source": [
"### Create the Retriever"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "nypubf9LRCdk"
},
"source": [
"Load the `gemini-2.0-flash` generative model with parameters."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "zi7c-8sxRACS"
},
"outputs": [],
"source": [
"# Initializing the Vertex AI Language model with required parameters\n",
"llm = VertexAI(\n",
" model=MULTIMODAL_MODEL,\n",
" max_output_tokens=2048,\n",
" temperature=0.2,\n",
" top_p=0.8,\n",
" top_k=40,\n",
" verbose=True,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "gwBobHo6jLO_"
},
"source": [
"Creates a retriever utilizing the Chroma vector store for similarity search.\n",
"\n",
"`search_kwargs={\"k\": 3}` - This parameter, specific to similarity search, dictates that the retriever should return the top 3 most relevant documents based on the calculated similarity scores.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "XbFtaHWPMmlA"
},
"outputs": [],
"source": [
"# Expose index to the retriever\n",
"retriever = db.as_retriever(search_type=\"similarity\", search_kwargs={\"k\": 3})"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "jdXK30NKa8cK"
},
"source": [
"Define a prompt template for a language model that consists of a string template. It accepts a set of parameters from the user that can be used to generate a prompt for a language model.\n",
"\n",
"More on [PromptTemplate](https://api.python.langchain.com/en/latest/prompts/langchain_core.prompts.prompt.PromptTemplate.html)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "-Mbb-3X_mFwl"
},
"outputs": [],
"source": [
"template = \"\"\"\n",
"You are a helpful AI assistant. You're tasked to answer the question given below, but only based on the context provided.\n",
"context:\n",
"<context>\n",
"{context}\n",
"</context>\n",
"\n",
"question:\n",
"<question>\n",
"{input}\n",
"</question>\n",
"\n",
"If you cannot find an answer ask the user to rephrase the question.\n",
"answer:\n",
"\n",
"\"\"\"\n",
"prompt = PromptTemplate.from_template(template)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "HOHivtVAmOtr"
},
"source": [
"Create the retrieval chain and invoke it by passing the question as an input."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "NL6r_Yn5GzlS"
},
"outputs": [],
"source": [
"# Create the retrieval chain\n",
"combine_docs_chain = create_stuff_documents_chain(llm, prompt)\n",
"retrieval_chain = create_retrieval_chain(retriever, combine_docs_chain)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "auqtXV1ijfQH"
},
"outputs": [],
"source": [
"# Invoke the retrieval chain\n",
"response = retrieval_chain.invoke({\"input\": \"Tell me about Figuring the EIC.\"})"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Tbbks_OV6ce0"
},
"outputs": [],
"source": [
"print(response[\"answer\"])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "1raHWPNlrnff"
},
"source": [
"### Example Questions:\n",
"\n",
"- Special rules for joint returns.\n",
"- Tell about persons not eligible for the standard deduction.\n",
"- Tell me about Figuring the EIC.\n",
"- Tell about contributions to Kay Bailey Hutchison Spousal IRAs.\n",
"- Tell about standard deduction for dependents.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ie7RLNMbHJnl"
},
"source": [
"## Interactive UI Widget for Question-Answering\n",
"\n",
"Enter your question in the input box and choose one of the options:\n",
"\n",
"**Ask Me!:** This option will generate an answer using similarity search on vector embeddings.\n",
"\n",
"**More Details:** Select this option to input the generated answer into a Large Language Model (LLM) for a more elaborate response."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "-Hu94QetHM5v"
},
"outputs": [],
"source": [
"button = widgets.Button(description=\"Ask Me!\")\n",
"output = widgets.Output()\n",
"button_stp = widgets.Button(description=\"More details\")\n",
"output = widgets.Output()\n",
"text = widgets.Text(\n",
" description=\"Question:\", layout=widgets.Layout(width=\"80%\", height=\"50px\")\n",
")\n",
"display(text, button, button_stp, output)\n",
"\n",
"\n",
"@output.capture()\n",
"def on_button_clicked(b):\n",
" clear_output()\n",
" question = text.value\n",
"\n",
" result = retrieval_chain.invoke({\"input\": question})\n",
" source_documents = list({doc.metadata[\"source\"] for doc in result[\"context\"]})\n",
"\n",
" print(\"\\nAnswer-\", result[\"answer\"])\n",
" print(\"\\nSource-\", \"\\n\".join(source_documents))\n",
" print(\"\\n\")\n",
"\n",
"\n",
"@output.capture()\n",
"def on_stp_clicked(b):\n",
" clear_output()\n",
" question = text.value\n",
" query = question + \"Give detailed information as much as possible. \"\n",
" result = retrieval_chain.invoke({\"input\": query})\n",
" source_documents = list({doc.metadata[\"source\"] for doc in result[\"context\"]})\n",
"\n",
" print(\"\\nAnswer-\", result[\"answer\"])\n",
" print(\"\\nSource-\", \"\\n\".join(source_documents))\n",
" print(\"\\n\")\n",
"\n",
"\n",
"button.on_click(on_button_clicked)\n",
"button_stp.on_click(on_stp_clicked)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "X33AAFNiC55l"
},
"source": [
"## Cleaning up"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "cJ2NCKA7RlkX"
},
"source": [
"Remove all the downloaded files and the vector database"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "_b56oorFHmS3"
},
"outputs": [],
"source": [
"!rm -r $INDEX_PATH\n",
"!rm -r $PERSIST_PATH"
]
}
],
"metadata": {
"colab": {
"name": "intra_knowledge_qna.ipynb",
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 0
}