search/tuning/vertexai-search-tuning.ipynb (1,551 lines of code) (raw):
{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "068fcf807336"
},
"source": [
"# Search tuning in Vertex AI Search\n",
"\n",
"<table align=\"center\">\n",
" <td style=\"text-align: center\" width=\"25%\">\n",
" <a href=\"https://colab.research.google.com/github/GoogleCloudPlatform/generative-ai/blob/main/search/tuning/vertexai-search-tuning.ipynb\">\n",
" <img width=\"32\" src=\"https://www.gstatic.com/pantheon/images/bigquery/welcome_page/colab-logo.svg\" alt=\"Google Colaboratory logo\"><br> Open in Colab\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\" width=\"25%\">\n",
" <a href=\"https://console.cloud.google.com/vertex-ai/colab/import/https:%2F%2Fraw.githubusercontent.com%2FGoogleCloudPlatform%2Fgenerative-ai%2Fmain%2Fsearch%2Ftuning%2Fvertexai-search-tuning.ipynb\">\n",
" <img width=\"32\" src=\"https://lh3.googleusercontent.com/JmcxdQi-qOpctIvWKgPtrzZdJJK-J3sWE1RsfjZNwshCFgE_9fULcNpuXYTilIR2hjwN\" alt=\"Google Cloud Colab Enterprise logo\"><br> Open in Colab Enterprise\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\" width=\"25%\">\n",
" <a href=\"https://console.cloud.google.com/vertex-ai/workbench/deploy-notebook?download_url=https://raw.githubusercontent.com/GoogleCloudPlatform/generative-ai/main/search/tuning/vertexai-search-tuning.ipynb\">\n",
" <img width=\"32\" src=\"https://www.gstatic.com/images/branding/gcpiconscolors/vertexai/v1/32px.svg\" alt=\"Vertex AI logo\"><br> Open in Vertex AI Workbench\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\" width=\"25%\">\n",
" <a href=\"https://github.com/GoogleCloudPlatform/generative-ai/blob/main/search/tuning/vertexai-search-tuning.ipynb\">\n",
" <img width=\"32\" src=\"https://upload.wikimedia.org/wikipedia/commons/9/91/Octicons-mark-github.svg\" alt=\"GitHub logo\"><br> View on GitHub\n",
" </a>\n",
" </td>\n",
"</table>\n",
"\n",
"<div style=\"clear: both;\"></div>\n",
" \n",
"<b>Share to:</b>\n",
"<table align=\"left\">\n",
" <td style=\"text-align: center\" width=\"10%\">\n",
" <a href=\"https://www.linkedin.com/sharing/share-offsite/?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/search/tuning/vertexai-search-tuning.ipynb\" target=\"_blank\">\n",
" <img width=\"20\" src=\"https://upload.wikimedia.org/wikipedia/commons/8/81/LinkedIn_icon.svg\" alt=\"LinkedIn logo\">\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\" width=\"10%\">\n",
" <a href=\"https://bsky.app/intent/compose?text=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/search/tuning/vertexai-search-tuning.ipynb\" target=\"_blank\">\n",
" <img width=\"20\" src=\"https://upload.wikimedia.org/wikipedia/commons/7/7a/Bluesky_Logo.svg\" alt=\"Bluesky logo\">\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\" width=\"10%\">\n",
" <a href=\"https://twitter.com/intent/tweet?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/search/tuning/vertexai-search-tuning.ipynb\" target=\"_blank\">\n",
" <img width=\"20\" src=\"https://upload.wikimedia.org/wikipedia/commons/5/53/X_logo_2023_original.svg\" alt=\"X logo\">\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\" width=\"10%\">\n",
" <a href=\"https://reddit.com/submit?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/search/tuning/vertexai-search-tuning.ipynb\" target=\"_blank\">\n",
" <img width=\"20\" src=\"https://redditinc.com/hubfs/Reddit%20Inc/Brand/Reddit_Logo.png\" alt=\"Reddit logo\">\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\" width=\"10%\">\n",
" <a href=\"https://www.facebook.com/sharer/sharer.php?u=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/search/tuning/vertexai-search-tuning.ipynb\" target=\"_blank\">\n",
" <img width=\"20\" src=\"https://upload.wikimedia.org/wikipedia/commons/5/51/Facebook_f_logo_%282019%29.svg\" alt=\"Facebook logo\">\n",
" </a>\n",
" </td>\n",
"</table> "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ca3c8a638e33"
},
"source": [
"| Author |\n",
"| --- |\n",
"| [Jincheol Kim](https://github.com/JincheolKim) |"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "80c810fbe603"
},
"source": [
"When users try to provide a search service over their archived documents and data, search performance may not meet the performance expectation all the time. The performance of Vertex AI Search can be measured in two aspects: the accuracy and the relevance of the search results, and the correctness of the summarized responses from the search results with correct annotations and references to the source document. Among the two aspects of the search performances, the accuracy and the relevance of the search results should be enhanced by generating embedding vectors which are more relevant semantically with document chunking and other document processing methods. The correctness of the summarized responses generated from the backend LLM (Gemini) behind the Vertex AI Search endpoint can be enhanced by tuning the backend LLM with some additional relevant data. The process of tuning the backend LLM with some domain-specific data is what Vertex AI Search Tuning is for.\n",
" \n",
"Before we tune the backend LLM behind Vertex AI Search, we should the prepare the raw text data in a specific JSONL format with a question-answer mapping file in the tab-separated table format. We will use some FAQ documents from an open source project (Kubernetes) to tune the backend LLM to enhance answers on the questions on Kubernetes. After we learn how we prepare the tuning data in JSONL and TSV format, we will learn how we can configure a search tuning job and submit it to Vertex AI.\n",
" \n",
"To learn more about the search tuning process, please refer to the following documents in the Google Cloud Documentation.\n",
" \n",
"- [Improve search results with search tuning](https://cloud.google.com/generative-ai-app-builder/docs/tune-search)\n",
"- [Create a search data store](https://cloud.google.com/generative-ai-app-builder/docs/create-data-store-es)\n",
"- [Create a search app](https://cloud.google.com/generative-ai-app-builder/docs/create-engine-es)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "11198a79d42c"
},
"source": [
"## Overview\n",
"\n",
"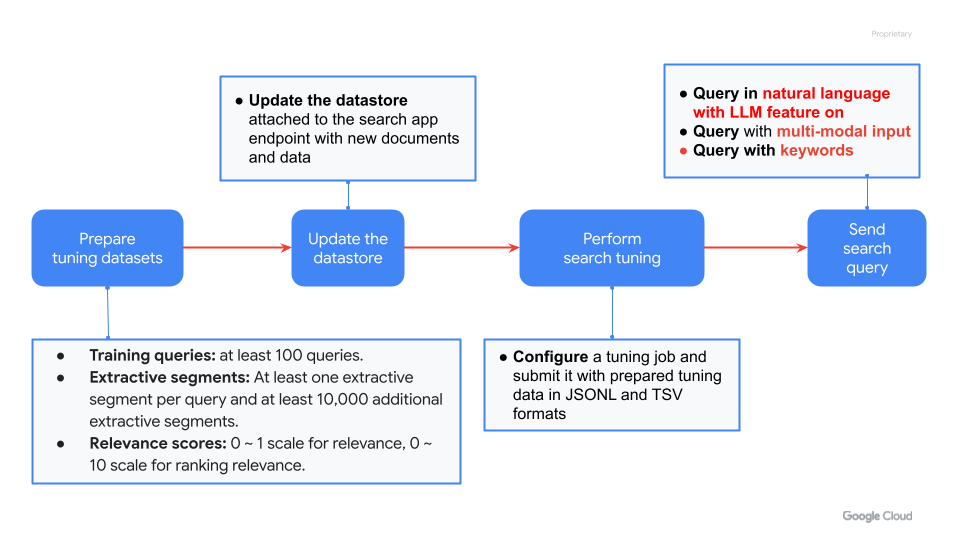\n",
"\n",
"* Prepare your data for tuning\n",
" - The datasets should be prepared in JSONL format with identifier-text pairs.\n",
" - The mapping between query and answer texts should be described in tab-separated values (TSV) formats.\n",
"* Update the datastore with the additional documents\n",
" - Before we update the datastore attached to the search app, the additional documents and data for tuning should be uploaded to the bucket in Cloud Storage.\n",
" - After uploading the new documents and data onto the bucket in Cloud Storage, the datastore is refreshed just by creating the datastore with the same configuration used in the previous creation. In the refresh process, we can see that only the files just added are used to generate new search indexes at the console interface.\n",
"* Rebuild the search app with the updated datastore\n",
" - After the refresh of the datastore is completed, the search app must be rebuilt to be connected to the updated datastore.\n",
"\n",
"In order to obtain the correct results with the additional documents and data, users must rebuild the search app after they rebuilt the datastore."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "4d998a5140b2"
},
"source": [
"## Get started"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "7de8816128de"
},
"source": [
"### Install Vertex AI SDK and other required packages\n",
"\n",
"We will install some dependencies to run the cells in this notebook. \n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "35b342466ed4"
},
"outputs": [],
"source": [
"%pip install --upgrade --user --quiet google-cloud-aiplatform google-cloud-discoveryengine langchain_google_community langchain langchain-google-vertexai langchain-google-community[vertexaisearch] shortuuid"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "f10b11bebfd1"
},
"source": [
"## Restart runtime\n",
"\n",
"To use the newly installed packages in this Jupyter runtime, you must restart the runtime. You can do this by running the cell below, which restarts the current kernel.\n",
"\n",
"The restart might take a minute or longer. After it has restarted, continue to the next step."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "d76628df8180"
},
"outputs": [],
"source": [
"import IPython\n",
"\n",
"app = IPython.Application.instance()\n",
"app.kernel.do_shutdown(True)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "7c12448f2e71"
},
"source": [
"## Authenticate your notebook environment (Colab only)\n",
"\n",
"If you're running this notebook on Google Colab, run the cell below to authenticate your environment."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "d8d593172549"
},
"outputs": [],
"source": [
"import os\n",
"import sys\n",
"\n",
"if \"google.colab\" in sys.modules:\n",
"\n",
" from google.colab import auth\n",
"\n",
" auth.authenticate_user()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8b3a2e9b94d5"
},
"source": [
"## Set Google Cloud project information and initialize Vertex AI SDK for Python\n",
"\n",
"To get started using Vertex AI, you must have an existing Google Cloud project and [enable the Vertex AI API](https://console.cloud.google.com/flows/enableapi?apiid=aiplatform.googleapis.com). Learn more about [setting up a project and a development environment](https://cloud.google.com/vertex-ai/docs/start/cloud-environment)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "1800f6c7238e"
},
"outputs": [],
"source": [
"import json\n",
"import logging\n",
"\n",
"# Imports common packages\n",
"import os\n",
"import platform\n",
"import re\n",
"import sys\n",
"\n",
"from google.api_core.client_options import ClientOptions\n",
"from google.api_core.operation import Operation\n",
"from google.cloud import discoveryengine\n",
"import shortuuid\n",
"import vertexai"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "efdd454efb6a"
},
"outputs": [],
"source": [
"!gcloud auth login"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "1875997de41d"
},
"outputs": [],
"source": [
"# Use the environment variable if the user doesn't provide Project ID.\n",
"PROJECT_ID = \"[your-project-id]\" # @param {type: \"string\", placeholder: \"[your-project-id]\", isTemplate: true}\n",
"if not PROJECT_ID or PROJECT_ID == \"[your-project-id]\":\n",
" PROJECT_ID = str(os.environ.get(\"GOOGLE_CLOUD_PROJECT\"))\n",
"\n",
"PROJECT_ID = \"genai-customersupport\"\n",
"LOCATION = \"global\"\n",
"STORAGE_LOCATION = \"us\"\n",
"\n",
"vertexai.init(project=PROJECT_ID, location=LOCATION)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "643f6d02011b"
},
"source": [
"## Create a Cloud Storage bucket\n",
"\n",
"Create a storage bucket to store intermediate artifacts such as datasets."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "f5c2d63395c1"
},
"outputs": [],
"source": [
"PUBLIC_DATA_SOURCE_URI = f\"gs://github-repo/generative-ai/search/tuning\"\n",
"BASE_DATA_SOURCE_URI = f\"gs://github-repo/generative-ai/search/tuning/awesome_rlhf\"\n",
"BUCKET_URI = f\"gs://sample-search-tuning-{PROJECT_ID}\" # @param {type:\"string\"}\n",
"TUNING_DATA_PATH_SOURCE = \"gs://github-repo/generative-ai/search/tuning/tuning_data\"\n",
"TUNING_DATA_PATH_LOCAL = f\"./tuning_data\"\n",
"TUNING_DATA_PATH_REMOTE = f\"{BUCKET_URI}/tuning_data\"\n",
"SEARCH_DATASTORE_PATH_REMOTE = f\"{BUCKET_URI}/rlhf-datastore\"\n",
"SEARCH_DATASTORE_ID = f\"search-datastore-{PROJECT_ID}-{shortuuid.uuid().lower()}\"\n",
"SEARCH_DATASTORE_NAME = \"RLHF-ARTICLE-DATASTORE\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "85597b5e35a8"
},
"source": [
"\"**If your bucket doesn't already exist**: Run the following cell to create your Cloud Storage bucket."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "abaea548b38b"
},
"outputs": [],
"source": [
"! gcloud storage buckets create --location={STORAGE_LOCATION} --project={PROJECT_ID} --enable-hierarchical-namespace --uniform-bucket-level-access -b {BUCKET_URI}\n",
"! mkdir $TUNING_DATA_PATH_LOCAL\n",
"! gcloud storage cp $TUNING_DATA_PATH_SOURCE/* $TUNING_DATA_PATH_LOCAL"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "c5b4068c0c26"
},
"source": [
"## Prepare the data\n",
"\n",
"We will use the following datasets for this notebook. \n",
"\n",
"(1) FAQ data from the open source projects Kubernetes and Kubernetes Client. This data is a short list of questions and answers which can be useful to test the working of this notebook in a short period of time.\n",
"\n",
"(2) BEIR ([Benchmarking IR datasets](https://github.com/beir-cellar/beir)): BEIR is a heterogeneous benchmark containing diverse IR tasks. It also provides a common and easy framework for evaluation of your NLP-based retrieval models within the benchmark. This public dataset is hosted in Google BigQuery and is included in BigQuery's 1TB/mo of free tier processing. This means that each user receives 1TB of free BigQuery processing every month, which can be used to run queries on this public dataset.\n",
" - For an overview, checkout our new wiki page: https://github.com/beir-cellar/beir/wiki.\n",
" - For models and datasets, checkout out Hugging Face (HF) page: https://huggingface.co/BeIR.\n",
" \n",
"(3) SciFact ([SciFact](https://huggingface.co/datasets/allenai/scifact)): SciFact, a dataset of 1.4K expert-written scientific claims paired with evidence-containing abstracts, and annotated with labels and rationales.\n",
" \n",
"For BEIR and SciFact, the datasets are already prepared in JSONL and TSV formats. You can use them for testing the search tuning feature without any data preprocessing chore. However, the amount of the data of the BEIR and SciFact is large which make the tuning job run too long. Given that, we will try to generate a small amount of the data first to check if the search tuning feature is working correctly with the FAQ data from the Kubernetes project."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "d7d8d04e32e5"
},
"source": [
"This ```generate_source_dataset``` function is a function to read the raw FAQ data from the FAQ and the README documents of the Kubernetes project and to generate the ```corpus_file.jsonl``` and ```query_file.jsonl``` for the tuning job."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "6958fb25e38f"
},
"outputs": [],
"source": [
"# Helper function to generate JSONL-format datasets for search tuning.\n",
"#\n",
"# Args:\n",
"# source_file (string): Path to the source files from which the JSONL\n",
"# files will be generated\n",
"# corpus_filepath (string): Path to the corpus file to which the JSONL\n",
"# formated corpus dataset file will be stored.\n",
"# query_filepath (string): Path to the query file to which the JSONL\n",
"# formated query dataset file will be stored.\n",
"# cleanup_at_start (bool, default=True): Clears the corpus files and\n",
"# the query files generated in the previous time\n",
"# before generating new datasets when the value\n",
"# is True\n",
"#\n",
"# Raises:\n",
"#\n",
"# Returns:\n",
"# No return values. Two JSONL files. (Corpus File, Query File)\n",
"\n",
"\n",
"def generate_source_dataset(\n",
" source_file: str,\n",
" corpus_filepath: str,\n",
" query_filepath: str,\n",
" cleanup_at_start: bool = True,\n",
"):\n",
" questions = []\n",
" answers = []\n",
"\n",
" # If cleanup_at_start is True, this section deletes the corpus files and\n",
" # the query files before generating new corpus and query files in JSONL\n",
" if cleanup_at_start:\n",
" if os.path.isfile(corpus_filepath):\n",
" print(f\"Removing previous file: %s\")\n",
" os.remove(corpus_filepath)\n",
" if os.path.isfile(query_filepath):\n",
" print(f\"Removing previous file: %s\")\n",
" os.remove(query_filepath)\n",
"\n",
" # This section generates a corpus file dataset in JSONL format\n",
" # from the source files.\n",
" logging.info(f\"{generate_source_dataset.__name__}: {1}\")\n",
" with open(source_file) as f:\n",
" line_str = f.readline()\n",
" answer = \"\"\n",
" answer_flag = False\n",
" while line_str:\n",
" if re.match(r\"^(#{3})\\s+(.+)$\", line_str):\n",
" question = re.split(r\"^(#{3})\\s+(.+)$\", line_str)\n",
" question_str = \"\"\n",
" len_question = len(question) - 1\n",
" reidx = 0\n",
" while not (question[len_question - reidx] == \"###\"):\n",
" question_str += question[len_question - reidx]\n",
" reidx += 1\n",
" questions.append(question_str)\n",
" # print(\"Question: %s\" % question_str)\n",
" answer_flag = True\n",
" answers.append(str.strip(answer, \"\"))\n",
" # print(\"Answer: %s\" % answer)\n",
" answer = \"\"\n",
" elif answer_flag == True:\n",
" answer += line_str\n",
" line_str = f.readline()\n",
"\n",
" logging.info(f\"{generate_source_dataset.__name__}: {2}\")\n",
" corpus_idx_start = 0\n",
" try:\n",
" with open(corpus_filepath) as cf:\n",
" corpus_idx_start = len(list(enumerate(cf)))\n",
" except:\n",
" corpus_idx_start = 0\n",
"\n",
" with open(corpus_filepath, \"a\") as cf:\n",
" jsonfile = \"\"\n",
" idx = corpus_idx_start\n",
" print(f\"start idx:%d\" % idx)\n",
" for answer in answers:\n",
" idx += 1\n",
" answer = answer.replace(\"\\\\[\", \"\\\\\\\\[\")\n",
" answer = answer.replace(\"\\\\]\", \"\\\\\\\\]\")\n",
" answer = answer.replace('\"', '\\\\\"')\n",
" json_line = '{{\"_id\": \"ans{:04d}\", \"text\": \"{}\" }}\\n'.format(\n",
" idx, str.strip(answer).replace(\"\\n\", \" \")\n",
" )\n",
" jsonfile += json_line\n",
" cf.writelines(jsonfile)\n",
"\n",
" # This section generates a query file dataset in JSONL format\n",
" # from the source files.\n",
" logging.info(f\"{generate_source_dataset.__name__}: {3}\")\n",
" query_idx_start = 0\n",
" try:\n",
" with open(query_filepath) as qf:\n",
" query_idx_start = len(list(enumerate(qf)))\n",
" except:\n",
" query_idx_start = 0\n",
"\n",
" with open(query_filepath, \"a\") as qf:\n",
" jsonfile = \"\"\n",
" idx = query_idx_start\n",
" print(f\"start idx:%d\" % idx)\n",
" for question in questions:\n",
" idx += 1\n",
" question = question.replace(\"\\\\[\", \"\\\\\\\\[\")\n",
" question = question.replace(\"\\\\]\", \"\\\\\\\\]\")\n",
" question = question.replace('\"', '\\\\\"')\n",
" json_line = '{{ \"_id\": \"que{:04d}\", \"text\": \"{}\" }}\\n'.format(\n",
" idx, str.strip(question).replace(\"\\n\", \" \")\n",
" )\n",
" jsonfile += json_line\n",
" qf.writelines(jsonfile)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "180fc88a543e"
},
"source": [
"This ```generate_training_test_dataset``` generates the query-answer mapping in a tab-separated value format to help the tuning job to map the queries and the texts for the answers to the queries from the FAQ."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "c241fd547498"
},
"outputs": [],
"source": [
"# Helper function to generate TSV(tab separated values)-format datasets\n",
"# to map the corpus file and the query file for search tuning.\n",
"#\n",
"# Args:\n",
"# corpus_filepath (string): Path to the corpus file to which the JSONL\n",
"# formated corpus dataset file will be stored.\n",
"# query_filepath (string): Path to the query file to which the JSONL\n",
"# formated query dataset file will be stored.\n",
"# training_filepath (string): Path to the mapping file between the entries\n",
"# in the corpus file and the query file to define\n",
"# a training dataset in TSV-format\n",
"# test_filepath (string): Path to the mapping file between the entries\n",
"# in the corpus file and the query file to define\n",
"# a test dataset in TSV-format\n",
"# cleanup_at_start (bool, default=True): Clears the training dataset files and\n",
"# the test dataset files generated in the previous time\n",
"# before generating new datasets when the value is True\n",
"#\n",
"# Raises:\n",
"#\n",
"# Returns:\n",
"# No return values. Two TSV files. (Training Dataset File, Test Dataset File)\n",
"\n",
"\n",
"def generate_training_test_dataset(\n",
" corpus_filepath: str,\n",
" query_filepath: str,\n",
" training_filepath: str,\n",
" test_filepath: str,\n",
" cleanup_at_start: bool = True,\n",
"):\n",
" questions = []\n",
" answers = []\n",
"\n",
" # If cleanup_at_start is True, this section deletes the training dataset files\n",
" # and the test dataset files before generating new TSV dataset files\n",
"\n",
" if cleanup_at_start:\n",
" if os.path.isfile(training_filepath):\n",
" print(f\"Removing previous file: %s\")\n",
" os.remove(training_filepath)\n",
" if os.path.isfile(test_filepath):\n",
" print(f\"Removing previous file: %s\")\n",
" os.remove(test_filepath)\n",
"\n",
" # Opens the corpus dataset file to generate the mapping between the corpus entries\n",
" # and the query entries\n",
"\n",
" with open(corpus_filepath) as corpus_file:\n",
" line_str = corpus_file.readline()\n",
" while line_str:\n",
" jsonl = json.loads(line_str, strict=False)\n",
" questions.append(jsonl[\"text\"])\n",
" line_str = corpus_file.readline()\n",
"\n",
" logging.info(f\"{generate_training_test_dataset.__name__}: {1}\")\n",
"\n",
" # Opens the query dataset file to generate the mapping between the corpus entries\n",
" # and the query entries\n",
"\n",
" with open(query_filepath) as query_file:\n",
" line_str = query_file.readline()\n",
" while line_str:\n",
" jsonl = json.loads(line_str, strict=False)\n",
" answers.append(jsonl[\"text\"])\n",
" line_str = query_file.readline()\n",
"\n",
" logging.info(f\"{generate_training_test_dataset.__name__}: {2}\")\n",
"\n",
" # Opens the training dataset file to generate the mapping between the corpus entries\n",
" # and the query entries\n",
"\n",
" with open(training_filepath, \"a\") as trf:\n",
" jsonfile = \"\"\n",
" json_line = \"query-id\\tcorpus-id\\tscore\\n\"\n",
" idx = 1\n",
" jsonfile += json_line\n",
" len_questions = len(questions)\n",
" for question in questions:\n",
" json_line = f\"que{idx:04d}\\tans{idx:04d}\\t1\\n\"\n",
" jsonfile += json_line\n",
" idx = idx + 1\n",
" if idx > 0.85 * len_questions:\n",
" break\n",
" trf.write(jsonfile)\n",
"\n",
" logging.info(f\"{generate_training_test_dataset.__name__}: {3}\")\n",
"\n",
" # Opens the test dataset file to generate the mapping between the corpus entries\n",
" # and the query entries\n",
"\n",
" with open(test_filepath, \"a\") as tef:\n",
" jsonfile = \"\"\n",
" json_line = \"query-id\\tcorpus-id\\tscore\\n\"\n",
" idx = 1\n",
" len_questions = len(questions)\n",
" jsonfile += json_line\n",
" for question in questions:\n",
" if idx <= 0.85 * len_questions:\n",
" idx = idx + 1\n",
" elif idx > 0.85 * len_questions and idx <= len_questions:\n",
" json_line = f\"que{idx:04d}\\tans{idx:04d}\\t1\\n\"\n",
" jsonfile += json_line\n",
" idx = idx + 1\n",
" tef.write(jsonfile)\n",
"\n",
" logging.info(f\"{generate_training_test_dataset.__name__}: {4}\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "038afd6614f5"
},
"outputs": [],
"source": [
"# Collects the generated JSONL and TSV files with PDF documents\n",
"# to update the search index after the search tuning\n",
"\n",
"\n",
"if __name__ == \"__main__\":\n",
" datasets = [\n",
" \"./tuning_data/FAQ.md\",\n",
" \"./tuning_data/FAQ-Kubernetes-Client.md\",\n",
" \"./tuning_data/README.md\",\n",
" ]\n",
" if os.path.isfile(\"./tuning_data/corpus_file.jsonl\"):\n",
" os.remove(\"./tuning_data/corpus_file.jsonl\")\n",
" if os.path.isfile(\"./tuning_data/query_file.jsonl\"):\n",
" os.remove(\"./tuning_data/query_file.jsonl\")\n",
"\n",
" for file in datasets:\n",
" print(file)\n",
" generate_source_dataset(\n",
" file,\n",
" \"./tuning_data/corpus_file.jsonl\",\n",
" \"./tuning_data/query_file.jsonl\",\n",
" cleanup_at_start=False,\n",
" )\n",
" generate_training_test_dataset(\n",
" \"./tuning_data/corpus_file.jsonl\",\n",
" \"./tuning_data/query_file.jsonl\",\n",
" \"./tuning_data/training_data.tsv\",\n",
" \"./tuning_data/test_data.tsv\",\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "2be63d1eccb3"
},
"source": [
"We create pdf files for the FAQ documents which are importable to the datastore of Vertex AI Search."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "8609d45b559b"
},
"outputs": [],
"source": [
"# Check if the system is macOS\n",
"if platform.system() == \"Darwin\":\n",
" # Install using Homebrew\n",
" !brew install xelatex # xelatex is used for pdf document creation in macOS.\n",
" !pandoc --pdf-engine=xelatex ./tuning_data/FAQ-Kubernetes-Client.md -o ./tuning_data/FAQ-Kubernetes-Client.pdf\n",
" !pandoc --pdf-engine=xelatex ./tuning_data/FAQ.md -o ./tuning_data/FAQ.pdf\n",
" !pandoc --pdf-engine=xelatex ./tuning_data/README.md -o ./tuning_data/README.pdf\n",
"elif platform.system() == \"Linux\":\n",
" # Install using apt-get for Ubuntu Linux\n",
" !sudo apt-get install pdflatex # pdflatex is used for pdf document creation in macOS.\n",
" !pandoc --pdf-engine=pdflatex ./tuning_data/FAQ-Kubernetes-Client.md -o ./tuning_data/FAQ-Kubernetes-Client.pdf\n",
" !pandoc --pdf-engine=pdflatex ./tuning_data/FAQ.md -o ./tuning_data/FAQ.pdf\n",
" !pandoc --pdf-engine=pdflatex ./tuning_data/README.md -o ./tuning_data/README.pdf"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ecaab399efba"
},
"source": [
"After generating the test tuning datasets, we will upload the datasets to the bucket in Cloud Storage which will be used as a data store for the search tuning."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "fc0b7bf1960f"
},
"outputs": [],
"source": [
"# Uploading the preprocessed data with the PDF files for reindexing to the search app data store\n",
"!echo \"Preprocessed tuning data: {TUNING_DATA_PATH_LOCAL}\"\n",
"!echo \"Destination path: {TUNING_DATA_PATH_REMOTE}\"\n",
"!gcloud storage folders create \"{TUNING_DATA_PATH_REMOTE}\"\n",
"!gcloud storage cp $TUNING_DATA_PATH_LOCAL/* $TUNING_DATA_PATH_REMOTE"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "30c11d2bc24c"
},
"source": [
"## Uploading data for a search app datastore (papers on RLHF)\n",
"\n",
"To create a Vertex AI search app, we will upload some pdf files on Reinforcement Learning on Human Feedback from [Awesome RLHF](https://github.com/opendilab/awesome-RLHF.git) github repository to a bucket in Cloud Storage which will be used as a search datastore. The pdf files are available at [Awesome RLHF - PDF Files](https://gitlab.com/jincheolkim/awesome-rlhf)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "e98fc0c02b96"
},
"outputs": [],
"source": [
"!echo {SEARCH_DATASTORE_PATH_REMOTE}\n",
"!gcloud storage folders create \"{SEARCH_DATASTORE_PATH_REMOTE}\"\n",
"!gcloud storage cp --recursive $BASE_DATA_SOURCE_URI/* $SEARCH_DATASTORE_PATH_REMOTE"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "772abea3560e"
},
"source": [
"## Helper functions to facilitate the following steps\n",
"\n",
"The following functions are helper functions to help you clear the steps to perform the search tuning without distraction on other details.\n",
"\n",
"* ```create_data_store```: function creates a datastore for an agent app with the identifier of a datastore with the ```data_store_id``` and the ```data_store_name```\n",
"* ```import_documents```: function imports documents from Cloud Storage to generate indices\n",
"* ```create_search_engine```: function creates a search agent app\n",
"* ```search```: function to perform a query with the query given through the argument\n",
"* ```train_custom_model```: function to tune the backend LLM for the search agent app\n",
"* ```delete_engine```: function to delete the search agent app\n",
"* ```purge_documents```: function to delete the index and the documents indexed for the search agent app\n",
"* ```delete_data_store```: function to delete the data store\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "9cfd1a1f9da2"
},
"outputs": [],
"source": [
"# For more information, refer to:\n",
"# https://cloud.google.com/generative-ai-app-builder/docs/locations#specify_a_multi-region_for_your_data_store\n",
"search_client_options = (\n",
" ClientOptions(api_endpoint=f\"{LOCATION}-discoveryengine.googleapis.com\")\n",
" if LOCATION != \"global\"\n",
" else None\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "0b3005f1e60e"
},
"outputs": [],
"source": [
"def create_data_store(\n",
" project_id: str,\n",
" location: str,\n",
" data_store_id: str,\n",
" data_store_name: str,\n",
" client_options: ClientOptions = search_client_options,\n",
") -> str:\n",
" client = discoveryengine.DataStoreServiceClient(client_options=client_options)\n",
"\n",
" # The full resource name of the collection\n",
" # e.g. projects/{project}/locations/{location}/collections/default_collection\n",
" parent = client.collection_path(\n",
" project=project_id,\n",
" location=location,\n",
" collection=\"default_collection\",\n",
" )\n",
"\n",
" data_store = discoveryengine.DataStore(\n",
" display_name=data_store_name,\n",
" # Options: GENERIC, MEDIA, HEALTHCARE_FHIR\n",
" industry_vertical=discoveryengine.IndustryVertical.GENERIC,\n",
" # Options: SOLUTION_TYPE_RECOMMENDATION, SOLUTION_TYPE_SEARCH, SOLUTION_TYPE_CHAT, SOLUTION_TYPE_GENERATIVE_CHAT\n",
" solution_types=[discoveryengine.SolutionType.SOLUTION_TYPE_SEARCH],\n",
" # Options: NO_CONTENT, CONTENT_REQUIRED, PUBLIC_WEBSITE\n",
" content_config=discoveryengine.DataStore.ContentConfig.CONTENT_REQUIRED,\n",
" )\n",
"\n",
" request = discoveryengine.CreateDataStoreRequest(\n",
" parent=parent,\n",
" data_store_id=data_store_id,\n",
" data_store=data_store,\n",
" # Optional: For Advanced Site Search Only\n",
" # create_advanced_site_search=True,\n",
" )\n",
"\n",
" # Make the request\n",
" operation = client.create_data_store(request=request)\n",
"\n",
" print(f\"Waiting for operation to complete: {operation.operation.name}\")\n",
" response = operation.result()\n",
"\n",
" # After the operation is complete,\n",
" # get information from operation metadata\n",
" metadata = discoveryengine.CreateDataStoreMetadata(operation.metadata)\n",
"\n",
" # Handle the response\n",
" print(response)\n",
" print(metadata)\n",
"\n",
" return operation.operation.name"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "e93b7aa62243"
},
"outputs": [],
"source": [
"def import_documents(\n",
" project_id: str,\n",
" location: str,\n",
" data_store_id: str,\n",
" client_options: ClientOptions = search_client_options,\n",
") -> discoveryengine.PurgeDocumentsMetadata:\n",
" client = discoveryengine.DocumentServiceClient(client_options=client_options)\n",
"\n",
" # The full resource name of the search engine branch.\n",
" # e.g. projects/{project}/locations/{location}/dataStores/{data_store_id}/branches/{branch}\n",
" parent = client.branch_path(\n",
" project=project_id,\n",
" location=location,\n",
" data_store=data_store_id,\n",
" branch=\"default_branch\",\n",
" )\n",
"\n",
" # With the new datastore, we will import and make an index over the documents in the datastore.\n",
" # The ```ImportDocumentsRequests``` generates a REST API request message in the JSON format\n",
" # and the ```import_documents``` method of the DocumentServiceClient class lets you import\n",
" # the documents and make an index over the document set with the information\n",
" # in the ```ImportDocumentRequest``` request.\n",
" document_import_request = discoveryengine.ImportDocumentsRequest(\n",
" parent=parent,\n",
" gcs_source=discoveryengine.GcsSource(\n",
" # Multiple URIs are supported\n",
" input_uris=[f\"{SEARCH_DATASTORE_PATH_REMOTE}/*\"],\n",
" # Options:\n",
" # - `content` - Unstructured documents (PDF, HTML, DOC, TXT, PPTX)\n",
" # - `custom` - Unstructured documents with custom JSONL metadata\n",
" # - `document` - Structured documents in the discoveryengine.Document format.\n",
" # - `csv` - Unstructured documents with CSV metadata\n",
" data_schema=\"content\",\n",
" ),\n",
" # Options: `FULL`, `INCREMENTAL`\n",
" reconciliation_mode=discoveryengine.ImportDocumentsRequest.ReconciliationMode.INCREMENTAL,\n",
" )\n",
"\n",
" # Make the request\n",
" operation = client.import_documents(request=document_import_request)\n",
"\n",
" print(f\"Waiting for operation to complete: {operation.operation.name}\")\n",
"\n",
" # After the operation is complete,\n",
" # get information from operation metadata\n",
" response = operation.result()\n",
" metadata = discoveryengine.ImportDocumentsMetadata(operation.metadata)\n",
"\n",
" # Handle the response\n",
" print(response)\n",
" print(metadata)\n",
"\n",
" return metadata"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "31066e205da3"
},
"outputs": [],
"source": [
"def create_search_engine(\n",
" project_id: str,\n",
" location: str,\n",
" engine_name: str,\n",
" engine_id: str,\n",
" data_store_ids: list[str],\n",
" client_options: ClientOptions = search_client_options,\n",
") -> str:\n",
" client = discoveryengine.EngineServiceClient(client_options=client_options)\n",
"\n",
" # The full resource name of the collection\n",
" # e.g. projects/{project}/locations/{location}/collections/default_collection\n",
" parent = client.collection_path(\n",
" project=project_id,\n",
" location=location,\n",
" collection=\"default_collection\",\n",
" )\n",
"\n",
" engine = discoveryengine.Engine(\n",
" display_name=engine_name,\n",
" # Options: GENERIC, MEDIA, HEALTHCARE_FHIR\n",
" industry_vertical=discoveryengine.IndustryVertical.GENERIC,\n",
" # Options: SOLUTION_TYPE_RECOMMENDATION, SOLUTION_TYPE_SEARCH, SOLUTION_TYPE_CHAT, SOLUTION_TYPE_GENERATIVE_CHAT\n",
" solution_type=discoveryengine.SolutionType.SOLUTION_TYPE_SEARCH,\n",
" # For search apps only\n",
" search_engine_config=discoveryengine.Engine.SearchEngineConfig(\n",
" # Options: SEARCH_TIER_STANDARD, SEARCH_TIER_ENTERPRISE\n",
" search_tier=discoveryengine.SearchTier.SEARCH_TIER_ENTERPRISE,\n",
" # Options: SEARCH_ADD_ON_LLM, SEARCH_ADD_ON_UNSPECIFIED\n",
" search_add_ons=[discoveryengine.SearchAddOn.SEARCH_ADD_ON_LLM],\n",
" ),\n",
" # For generic recommendation apps only\n",
" # similar_documents_config=discoveryengine.Engine.SimilarDocumentsEngineConfig,\n",
" data_store_ids=data_store_ids,\n",
" )\n",
"\n",
" request = discoveryengine.CreateEngineRequest(\n",
" parent=parent,\n",
" engine=engine,\n",
" engine_id=engine_id,\n",
" )\n",
"\n",
" # Make the request\n",
" operation = client.create_engine(request=request)\n",
"\n",
" print(f\"Waiting for operation to complete: {operation.operation.name}\")\n",
" response = operation.result()\n",
"\n",
" # After the operation is complete,\n",
" # get information from operation metadata\n",
" metadata = discoveryengine.CreateEngineMetadata(operation.metadata)\n",
"\n",
" # Handle the response\n",
" print(response)\n",
" print(metadata)\n",
"\n",
" return operation.operation.name"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "726bf37f458a"
},
"outputs": [],
"source": [
"def search(\n",
" project_id: str,\n",
" location: str,\n",
" engine_id: str,\n",
" search_query: str,\n",
" client_options: ClientOptions = search_client_options,\n",
") -> list[discoveryengine.SearchResponse]:\n",
" client = discoveryengine.SearchServiceClient(client_options=client_options)\n",
"\n",
" # The full resource name of the search app serving config\n",
" serving_config = f\"projects/{project_id}/locations/{location}/collections/default_collection/engines/{engine_id}/servingConfigs/default_config\"\n",
"\n",
" # Optional - only supported for unstructured data: Configuration options for search.\n",
" # Refer to the `ContentSearchSpec` reference for all supported fields:\n",
" # https://cloud.google.com/python/docs/reference/discoveryengine/latest/google.cloud.discoveryengine_v1.types.SearchRequest.ContentSearchSpec\n",
" content_search_spec = discoveryengine.SearchRequest.ContentSearchSpec(\n",
" # For information about snippets, refer to:\n",
" # https://cloud.google.com/generative-ai-app-builder/docs/snippets\n",
" snippet_spec=discoveryengine.SearchRequest.ContentSearchSpec.SnippetSpec(\n",
" return_snippet=True\n",
" ),\n",
" # For information about search summaries, refer to:\n",
" # https://cloud.google.com/generative-ai-app-builder/docs/get-search-summaries\n",
" summary_spec=discoveryengine.SearchRequest.ContentSearchSpec.SummarySpec(\n",
" summary_result_count=5,\n",
" include_citations=True,\n",
" ignore_adversarial_query=True,\n",
" ignore_non_summary_seeking_query=True,\n",
" model_prompt_spec=discoveryengine.SearchRequest.ContentSearchSpec.SummarySpec.ModelPromptSpec(\n",
" preamble=\"YOUR_CUSTOM_PROMPT\"\n",
" ),\n",
" model_spec=discoveryengine.SearchRequest.ContentSearchSpec.SummarySpec.ModelSpec(\n",
" version=\"stable\",\n",
" ),\n",
" ),\n",
" )\n",
"\n",
" # Refer to the `SearchRequest` reference for all supported fields:\n",
" # https://cloud.google.com/python/docs/reference/discoveryengine/latest/google.cloud.discoveryengine_v1.types.SearchRequest\n",
" request = discoveryengine.SearchRequest(\n",
" serving_config=serving_config,\n",
" query=search_query,\n",
" page_size=10,\n",
" content_search_spec=content_search_spec,\n",
" query_expansion_spec=discoveryengine.SearchRequest.QueryExpansionSpec(\n",
" condition=discoveryengine.SearchRequest.QueryExpansionSpec.Condition.AUTO,\n",
" ),\n",
" spell_correction_spec=discoveryengine.SearchRequest.SpellCorrectionSpec(\n",
" mode=discoveryengine.SearchRequest.SpellCorrectionSpec.Mode.AUTO\n",
" ),\n",
" )\n",
"\n",
" response = client.search(request)\n",
" print(response)\n",
"\n",
" return response"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "23b351587b01"
},
"outputs": [],
"source": [
"def train_custom_model(\n",
" project_id: str,\n",
" location: str,\n",
" data_store_id: str,\n",
" corpus_data_path: str,\n",
" query_data_path: str,\n",
" train_data_path: str,\n",
" test_data_path: str,\n",
" client_options: ClientOptions = search_client_options,\n",
") -> Operation:\n",
" client = discoveryengine.SearchTuningServiceClient(client_options=client_options)\n",
"\n",
" # The full resource name of the data store\n",
" data_store = f\"projects/{project_id}/locations/{location}/collections/default_collection/dataStores/{data_store_id}\"\n",
"\n",
" # Make the request\n",
" operation = client.train_custom_model(\n",
" request=discoveryengine.TrainCustomModelRequest(\n",
" gcs_training_input=discoveryengine.TrainCustomModelRequest.GcsTrainingInput(\n",
" corpus_data_path=corpus_data_path,\n",
" query_data_path=query_data_path,\n",
" train_data_path=train_data_path,\n",
" test_data_path=test_data_path,\n",
" ),\n",
" data_store=data_store,\n",
" model_type=\"search-tuning\",\n",
" )\n",
" )\n",
"\n",
" # Optional: Wait for training to complete\n",
" print(f\"Waiting for operation to complete: {operation.operation.name}\")\n",
" response = operation.result()\n",
"\n",
" # After the operation is complete,\n",
" # get information from operation metadata\n",
" metadata = discoveryengine.TrainCustomModelMetadata(operation.metadata)\n",
"\n",
" # Handle the response\n",
" print(response)\n",
" print(metadata)\n",
" print(operation)\n",
"\n",
" return operation"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "4431a0cac4f5"
},
"outputs": [],
"source": [
"def delete_engine(\n",
" project_id: str,\n",
" location: str,\n",
" engine_id: str,\n",
" client_options: ClientOptions = search_client_options,\n",
") -> str:\n",
" client = discoveryengine.EngineServiceClient(client_options=client_options)\n",
"\n",
" # The full resource name of the engine\n",
" # e.g. projects/{project}/locations/{location}/collections/default_collection/engines/{engine_id}\n",
" name = client.engine_path(\n",
" project=project_id,\n",
" location=location,\n",
" collection=\"default_collection\",\n",
" engine=engine_id,\n",
" )\n",
"\n",
" # Make the request\n",
" operation = client.delete_engine(name=name)\n",
"\n",
" print(f\"Operation: {operation.operation.name}\")\n",
"\n",
" return operation.operation.name"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "d695940875b4"
},
"outputs": [],
"source": [
"def purge_documents(\n",
" project_id: str,\n",
" location: str,\n",
" data_store_id: str,\n",
" client_options: ClientOptions = search_client_options,\n",
") -> discoveryengine.PurgeDocumentsMetadata:\n",
" client = discoveryengine.DocumentServiceClient(client_options=client_options)\n",
"\n",
" operation = client.purge_documents(\n",
" request=discoveryengine.PurgeDocumentsRequest(\n",
" # The full resource name of the search engine branch.\n",
" # e.g. projects/{project}/locations/{location}/dataStores/{data_store_id}/branches/{branch}\n",
" parent=client.branch_path(\n",
" project=project_id,\n",
" location=location,\n",
" data_store=data_store_id,\n",
" branch=\"default_branch\",\n",
" ),\n",
" filter=\"*\",\n",
" # If force is set to `False`, return the expected purge count without deleting any documents.\n",
" force=True,\n",
" )\n",
" )\n",
"\n",
" print(f\"Waiting for operation to complete: {operation.operation.name}\")\n",
" response = operation.result()\n",
"\n",
" # After the operation is complete,\n",
" # get information from operation metadata\n",
" metadata = discoveryengine.PurgeDocumentsMetadata(operation.metadata)\n",
"\n",
" # Handle the response\n",
" print(response)\n",
" print(metadata)\n",
"\n",
" return metadata"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "dea04a3478cb"
},
"outputs": [],
"source": [
"def delete_data_store(\n",
" project_id: str,\n",
" location: str,\n",
" data_store_id: str,\n",
" client_options: ClientOptions = search_client_options,\n",
") -> str:\n",
" client = discoveryengine.DataStoreServiceClient(client_options=client_options)\n",
"\n",
" request = discoveryengine.DeleteDataStoreRequest(\n",
" # The full resource name of the data store\n",
" name=client.data_store_path(project_id, location, data_store_id)\n",
" )\n",
"\n",
" # Make the request\n",
" operation = client.delete_data_store(request=request)\n",
"\n",
" print(f\"Operation: {operation.operation.name}\")\n",
"\n",
" return operation.operation.name"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "df2d7e8fc6e6"
},
"source": [
"## Creating a data store for a search app with the cloud storage bucket with PDF documents\n",
"\n",
"We create a datastore with the datastore bucket in Cloud Storage with the PDF files on RLHF and import them to generate indices for search."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "588af607bc6d"
},
"outputs": [],
"source": [
"!echo \"Datastore ID: {SEARCH_DATASTORE_ID}\"\n",
"!echo \"Datastore Name: {SEARCH_DATASTORE_NAME}\"\n",
"create_datastore_op_name = create_data_store(\n",
" PROJECT_ID, LOCATION, SEARCH_DATASTORE_ID, SEARCH_DATASTORE_NAME\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "765dcf64879d"
},
"outputs": [],
"source": [
"metadata = import_documents(PROJECT_ID, LOCATION, SEARCH_DATASTORE_ID)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "acdb037fce28"
},
"source": [
"## Creating a search app using the Vertex AI Search SDK\n",
"\n",
"As we just created a datastore and made an index over the documents in it in the above, we will create a search app with the datastore. \n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "f549f8d5091f"
},
"outputs": [],
"source": [
"SEARCH_DATASTORE_REF_ID = f\"projects/{PROJECT_ID}/locations/{LOCATION}/collections/default_collection/dataStores/{SEARCH_DATASTORE_ID}\"\n",
"SEARCH_APP_ID = f\"search-app-{PROJECT_ID}-{shortuuid.uuid().lower()}\"\n",
"SEARCH_APP_NAME = \"RLHF_SEARCH_APP\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "10a707979daf"
},
"outputs": [],
"source": [
"create_search_app_op_name = create_search_engine(\n",
" PROJECT_ID, LOCATION, SEARCH_APP_NAME, SEARCH_APP_ID, [SEARCH_DATASTORE_ID]\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "3862d318d1ad"
},
"source": [
"### Test the search app with a test prompt\n",
"\n",
"We will test the search app we just created with information about a paper regarding a world model for autonomous driving which is described in a paper among the documents in the datastore."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "68365934e4b2"
},
"outputs": [],
"source": [
"QUERY_PROMPT = \"\"\"\n",
" What is the name of the world model for autonomous driving developed recently?\n",
"\"\"\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "bad64c16adca"
},
"source": [
"We can see that the search app returns a list of relevant documents with references to the related documents in the datastore. Please keep the \n",
"result in your mind to compare it with the results after the search tuning is performed."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "fc7cd4f71bbc"
},
"outputs": [],
"source": [
"search_response = search(PROJECT_ID, LOCATION, SEARCH_APP_ID, QUERY_PROMPT)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "3c307dc82f9f"
},
"source": [
"## Configuring and submitting a search tuning job\n",
"\n",
"With the search app ready, we will perform a search tuning with a test tuning data on Kubernetes.\n",
"\n",
"First, we will upload the documents of FAQs about Kubernetes and Kubernetes Client API. The original documents were in the Markdown format but we transform them to PDF format files as the Vertex AI Search cannot accept Markdown files but only HTML, PDF and PDF with embedded text, TXT, JSON, XHTML, and XML format. PPTX, DOCX and XLSX formats are available in Preview. The PDF files are uploaded to the buckets for the datastore of the search app."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "5bd5eb9e64ee"
},
"source": [
"#### Uploading the additional PDF files for tuning to the bucket of the datastore"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "0741318fcd32"
},
"outputs": [],
"source": [
"!gcloud storage cp {TUNING_DATA_PATH_LOCAL}/*.jsonl \"{TUNING_DATA_PATH_REMOTE}\"\n",
"!gcloud storage cp {TUNING_DATA_PATH_LOCAL}/*.tsv \"{TUNING_DATA_PATH_REMOTE}\"\n",
"!gcloud storage ls \"{TUNING_DATA_PATH_REMOTE}\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "53d377765df5"
},
"source": [
"#### Uploading the datasets for the search tuning and perform the tuning\n",
"\n",
"These are the information on the tuning dataset files to be used to tune the backend LLM behind the search app. Please refer to the [Prepare data for ingesting](https://cloud.google.com/generative-ai-app-builder/docs/prepare-data#website) in the Google Cloud Documentation."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "b91ea4e8b7a5"
},
"outputs": [],
"source": [
"data_store_id = f\"{SEARCH_DATASTORE_ID}\"\n",
"corpus_data_path = f\"{TUNING_DATA_PATH_REMOTE}/corpus_file.jsonl\"\n",
"query_data_path = f\"{TUNING_DATA_PATH_REMOTE}/query_file.jsonl\"\n",
"train_data_path = f\"{TUNING_DATA_PATH_REMOTE}/training_data.tsv\"\n",
"test_data_path = f\"{TUNING_DATA_PATH_REMOTE}/test_data.tsv\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "1a44073dbafc"
},
"source": [
"This ```train_custom_model``` function is to submit a search tuning job with the datasets we just prepared."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "47206888e8e1"
},
"outputs": [],
"source": [
"tuning_op = train_custom_model(\n",
" PROJECT_ID,\n",
" LOCATION,\n",
" data_store_id,\n",
" corpus_data_path,\n",
" query_data_path,\n",
" train_data_path,\n",
" test_data_path,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "a0e334074066"
},
"source": [
"We can see that three additional documents related to the tuning task was uploaded to the datastore bucket, ```FAQ-Kubernetes-Client.pdf, FAQ.pdf, README.pdf.``` With these new documents, we should perform the indexing again by calling the ```import_documents``` method of the client again."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "3c3d193b5c3e"
},
"outputs": [],
"source": [
"!gcloud storage cp \"{TUNING_DATA_PATH_LOCAL}/*.pdf\" \"{SEARCH_DATASTORE_PATH_REMOTE}\"\n",
"!gcloud storage ls \"{SEARCH_DATASTORE_PATH_REMOTE}\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "17191f107297"
},
"outputs": [],
"source": [
"metadata = import_documents(PROJECT_ID, LOCATION, SEARCH_DATASTORE_ID)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "32c8827f86e6"
},
"source": [
"#### Testing the tuned search app endpoint with a question on Kubernetes\n",
"\n",
"The tuning job will take about 30 to 60 minutes. After the tuning job completed, we test the search app with a query prompt regarding Kubernetes which is the information in the documents indexed additionally with the tuning."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "214b65078ce4"
},
"outputs": [],
"source": [
"QUERY_PROMPT = \"\"\"\n",
" How do I determine the status of a deployment of Kubernetes?\n",
"\"\"\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "aa567f3c38eb"
},
"source": [
"We can see that the information on the deployment of Kubernetes which was described in the FAQ documents are correctly returned with the new documents indexed in the tuning."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "cdbb758533ef"
},
"outputs": [],
"source": [
"search_response = search(PROJECT_ID, LOCATION, SEARCH_APP_ID, QUERY_PROMPT)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "f717e9cb30e7"
},
"source": [
"## Clean up\n",
"\n",
"We should clean up the deployed resources and data not to create unnecessary costs."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "2b2bf33f37c7"
},
"source": [
"#### Deleting the search app"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "82138114c3bb"
},
"outputs": [],
"source": [
"delete_search_app_op_name = delete_engine(PROJECT_ID, LOCATION, SEARCH_APP_ID)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ba60668eb8bc"
},
"source": [
"#### Deleting the documents in the datastore"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "a76b43ef3767"
},
"outputs": [],
"source": [
"purge_document_metadata = purge_documents(PROJECT_ID, LOCATION, SEARCH_DATASTORE_ID)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "80f199d6f782"
},
"source": [
"#### Deleting the datastore"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ac2f897cf840"
},
"outputs": [],
"source": [
"delete_datastore_op_name = delete_data_store(PROJECT_ID, LOCATION, SEARCH_DATASTORE_ID)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "2d0d394cb942"
},
"outputs": [],
"source": [
"!gcloud storage rm -r \"{BUCKET_URI}\""
]
}
],
"metadata": {
"colab": {
"name": "vertexai-search-tuning.ipynb",
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 0
}