workshops/qa-ops/intro_Vertex_AI_embeddings.ipynb (1,675 lines of code) (raw):
{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ijGzTHJJUCPY"
},
"outputs": [],
"source": [
"# Copyright 2024 Google LLC\n",
"#\n",
"# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
"# you may not use this file except in compliance with the License.\n",
"# You may obtain a copy of the License at\n",
"#\n",
"# https://www.apache.org/licenses/LICENSE-2.0\n",
"#\n",
"# Unless required by applicable law or agreed to in writing, software\n",
"# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
"# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
"# See the License for the specific language governing permissions and\n",
"# limitations under the License."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "NDsTUvKjwHBW"
},
"source": [
"# Introduction to Vertex AI Embeddings - Text & Multimodal\n",
"\n",
"<table align=\"left\">\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://colab.research.google.com/github/GoogleCloudPlatform/generative-ai/blob/main/workshops/qa-ops/intro_vertex_ai_embeddings.ipynb\">\n",
" <img width=\"32px\" src=\"https://www.gstatic.com/pantheon/images/bigquery/welcome_page/colab-logo.svg\" alt=\"Google Colaboratory logo\"><br> Run in Colab\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://console.cloud.google.com/vertex-ai/colab/import/https:%2F%2Fraw.githubusercontent.com%2FGoogleCloudPlatform%2Fgenerative-ai%2Fmain%2Fworkshops%2Fqa-ops%2Fintro_vertex_ai_embeddings.ipynb\">\n",
" <img width=\"32px\" src=\"https://lh3.googleusercontent.com/JmcxdQi-qOpctIvWKgPtrzZdJJK-J3sWE1RsfjZNwshCFgE_9fULcNpuXYTilIR2hjwN\" alt=\"Google Cloud Colab Enterprise logo\"><br> Run in Colab Enterprise\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/qa-ops/intro_vertex_ai_embeddings.ipynb\">\n",
" <img width=\"32px\" src=\"https://www.svgrepo.com/download/217753/github.svg\" alt=\"GitHub logo\"><br> View on GitHub\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://console.cloud.google.com/vertex-ai/workbench/deploy-notebook?download_url=https://raw.githubusercontent.com/GoogleCloudPlatform/generative-ai/main/workshops/qa-ops/intro_vertex_ai_embeddings.ipynb\">\n",
" <img src=\"https://www.gstatic.com/images/branding/gcpiconscolors/vertexai/v1/32px.svg\" alt=\"Vertex AI logo\"><br> Open in Vertex AI Workbench\n",
" </a>\n",
" </td> \n",
"</table>\n",
"\n",
"<div style=\"clear: both;\"></div>\n",
"\n",
"<b>Share to:</b>\n",
"\n",
"<a href=\"https://www.linkedin.com/sharing/share-offsite/?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/qa-ops/intro_vertex_ai_embeddings.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/8/81/LinkedIn_icon.svg\" alt=\"LinkedIn logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://bsky.app/intent/compose?text=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/qa-ops/intro_vertex_ai_embeddings.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/7/7a/Bluesky_Logo.svg\" alt=\"Bluesky logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://twitter.com/intent/tweet?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/qa-ops/intro_vertex_ai_embeddings.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/5/5a/X_icon_2.svg\" alt=\"X logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://reddit.com/submit?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/qa-ops/intro_vertex_ai_embeddings.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://redditinc.com/hubfs/Reddit%20Inc/Brand/Reddit_Logo.png\" alt=\"Reddit logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://www.facebook.com/sharer/sharer.php?u=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/qa-ops/intro_vertex_ai_embeddings.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/5/51/Facebook_f_logo_%282019%29.svg\" alt=\"Facebook logo\">\n",
"</a> "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "4uoRmYQsKBgl"
},
"source": [
"| | |\n",
"|-|-|\n",
"|Author(s) | [Lavi Nigam](https://github.com/lavinigam-gcp) , [Kaz Sato]() |"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "VK1Q5ZYdVL4Y"
},
"source": [
"## Overview\n",
"\n",
"In this notebook, you will explore Vertex AI Embeddings API for both Text and Multimodal (Images and Video). Before we jump right into it, let's understand what are embeddings?\n",
"\n",
"\n",
"**Embeddings: Translating Content into the Language of Numbers**\n",
"\n",
"Imagine you're trying to describe a friend's personality to someone else. You could use words like \"kind,\" \"energetic,\" or \"thoughtful.\" But wouldn't it be cool if you could assign a set of numbers to each of these qualities to create a unique code for your friend?\n",
"\n",
"Embeddings do something similar for various types of content:\n",
"\n",
"* **For text:** Each word, sentence, or even an entire document gets transformed into a list of numbers (a vector). These numbers capture the meaning and relationships between words. For example, the word \"cat\" might be represented as [0.25, -0.18, 0.93...], while \"kitten\" could be [0.30, -0.16, 0.88...]. The close proximity of these vectors indicates a semantic connection.\n",
"\n",
"\n",
"* **For images:** Instead of pixels, an image becomes a vector that represents the visual features in the image. A picture of a sunny beach might get translated into [0.85, 0.42, -0.05...], while a snowy mountain might be [-0.32, 0.78, 0.12...].\n",
"\n",
"\n",
"* **For video:** Each frame or even the entire video sequence gets a numerical representation that encapsulates the visual content, movement, and potentially even audio information.\n",
"\n",
"\n",
"Let's take another example: Imagine you have a giant box of mismatched items: books, photographs, movie DVDs, and more. Each item is unique and complex, but you want to organize them in a way that makes sense. Embeddings do this, but for data like text, images, and videos.\n",
"\n",
"\n",
"Essentially, embeddings are like secret codes that represent your data in a simplified way. Think of them as numerical coordinates on a map. Similar items (like books on the same topic or photos of the same place) will be close to each other on this map, while very different items will be far apart.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "HjB8ZjusCQn6"
},
"source": [
"**Why Do We Need Embeddings?**\n",
"\n",
"Computers are great at crunching numbers, but they struggle to understand raw text, images, or videos. Embeddings act like a translator, converting these complex things into a format computers can easily work with. This opens up a world of possibilities for tasks like:\n",
"\n",
"\n",
"* **Finding Similarities:** By comparing the numbers in these vectors, you can easily determine how similar or different pieces of content are. Think of it as a way to measure the \"distance\" between meanings. This allows you to:\n",
"\n",
" - Find documents with related topics\n",
" - Discover visually similar images\n",
" - Group videos with similar content\n",
"\n",
"* **Searching and Recommending:** Imagine you're looking for a specific image, but you don't have the right keywords to search for it. With embeddings, you can simply provide an example image, and the search engine can find other images that are similar in visual style or content.\n",
"\n",
"\n",
"* **Machine Learning and AI:** Embeddings are the backbone of many modern AI applications. They are used to train models that can understand and generate text, classify images, translate languages, and even create art."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "SCFSGAolERQI"
},
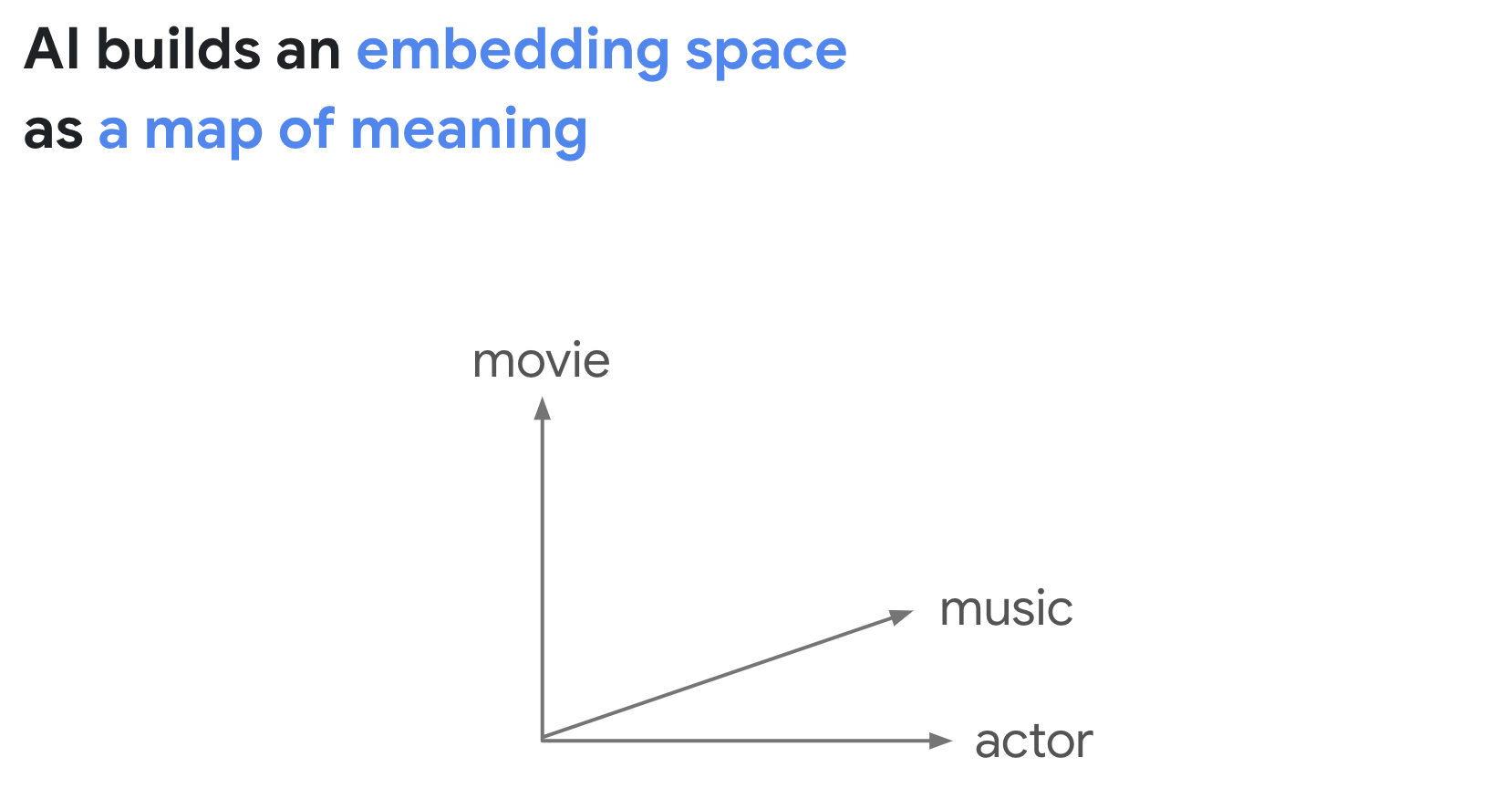
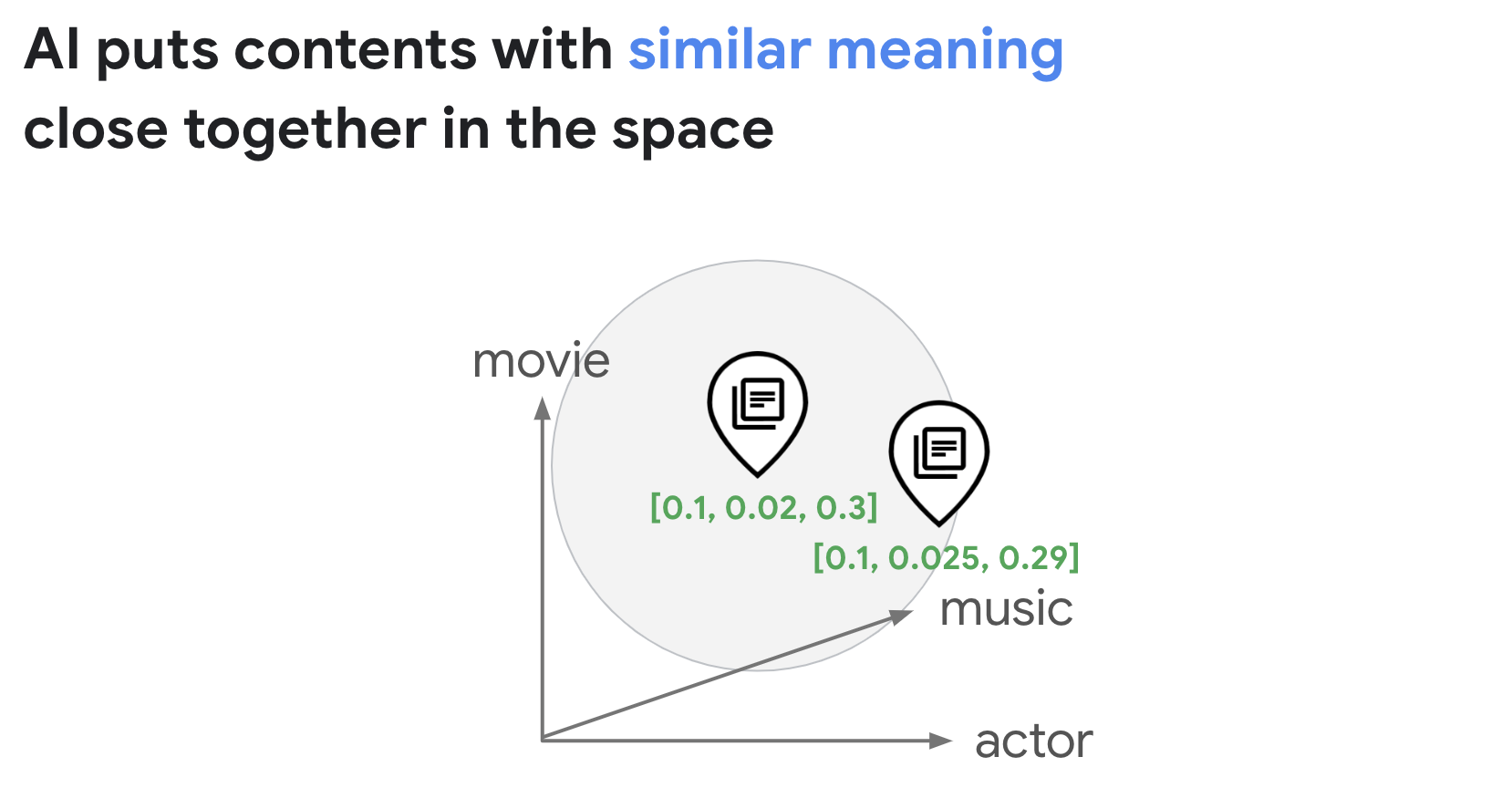
"source": [
"nce trained with specific content like text, images, or any content, AI creates a space called \"embedding space\", which is essentially a map of the content's meaning.\n",
"\n",
"\n",
"\n",
"AI can identify the location of each content on the map, that's what embedding is.\n",
"\n",
"\n",
"\n",
"Let's take an example where a text discusses movies, music, and actors, with a distribution of 10%, 2%, and 30%, respectively. In this case, the AI can create an embedding with three values: 0.1, 0.02, and 0.3, in 3 dimensional space.\n",
"\n",
"\n",
"\n",
"AI can put content with similar meanings closely together in the space."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "JWVXvBnAEY8w"
},
"source": [
"AI and Embeddings are now playing a crucial role in creating a new way of human-computer interaction.\n",
"\n",
"\n",
"\n",
"AI organizes data into embeddings, which represent what the user is looking for, the meaning of contents, or many other things you have in your business. This creates a new level of user experience that is becoming the new standard.\n",
"\n",
"To learn more about embeddings, [Foundational courses: Embeddings on Google Machine Learning Crush Course](https://developers.google.com/machine-learning/crash-course/embeddings/video-lecture) and [Meet AI's multitool: Vector embeddings by Dale Markowitz](https://cloud.google.com/blog/topics/developers-practitioners/meet-ais-multitool-vector-embeddings) are great materials.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "RQT500QqVPIb"
},
"source": [
"### Objectives\n",
"\n",
"In this notebook, you will explore:\n",
"* Vertex AI Text Embeddings API\n",
"* Vertex AI Multimodal Embeddings API (Images & Video)\n",
"* Building simple search with e-commerce data\n",
" - Find product based on text query\n",
" - Find product based on image\n",
" - Find Video based on video\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "KnpYxfesh2rI"
},
"source": [
"### Costs\n",
"\n",
"This tutorial uses billable components of Google Cloud:\n",
"\n",
"- Vertex AI\n",
"\n",
"Learn about [Vertex AI pricing](https://cloud.google.com/vertex-ai/pricing) and use the [Pricing Calculator](https://cloud.google.com/products/calculator/) to generate a cost estimate based on your projected usage.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "DXJpXzKrh2rJ"
},
"source": [
"## Getting Started\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "N5afkyDMSBW5"
},
"source": [
"### Install Vertex AI SDK for Python and other dependencies\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "kc4WxYmLSBW5"
},
"outputs": [],
"source": [
"%pip install --upgrade --user google-cloud-aiplatform"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "R5Xep4W9lq-Z"
},
"source": [
"### Restart current runtime\n",
"\n",
"To use the newly installed packages in this Jupyter runtime, you must restart the runtime. You can do this by running the cell below, which will restart the current kernel."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "XRvKdaPDTznN"
},
"outputs": [],
"source": [
"# Restart kernel after installs so that your environment can access the new packages\n",
"import IPython\n",
"\n",
"app = IPython.Application.instance()\n",
"app.kernel.do_shutdown(True)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "SbmM4z7FOBpM"
},
"source": [
"<div class=\"alert alert-block alert-warning\">\n",
"<b>⚠️ The kernel is going to restart. Please wait until it is finished before continuing to the next step. ⚠️</b>\n",
"</div>\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "FtsU9Bw9h2rL"
},
"source": [
"### Authenticate your notebook environment (Colab only)\n",
"\n",
"If you are running this notebook on Google Colab, run the following cell to authenticate your environment. This step is not required if you are using [Vertex AI Workbench](https://cloud.google.com/vertex-ai-workbench).\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "GpYEyLsOh2rL"
},
"outputs": [],
"source": [
"import sys\n",
"\n",
"# Additional authentication is required for Google Colab\n",
"if \"google.colab\" in sys.modules:\n",
" # Authenticate user to Google Cloud\n",
" from google.colab import auth\n",
"\n",
" auth.authenticate_user()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "O1vKZZoEh2rL"
},
"source": [
"### Set Google Cloud project information and initialize Vertex AI SDK\n",
"\n",
"To get started using Vertex AI, you must have an existing Google Cloud project and [enable the Vertex AI API](https://console.cloud.google.com/flows/enableapi?apiid=aiplatform.googleapis.com).\n",
"\n",
"Learn more about [setting up a project and a development environment](https://cloud.google.com/vertex-ai/docs/start/cloud-environment)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "gJqZ76rJh2rM"
},
"outputs": [],
"source": [
"# Define project information\n",
"\n",
"import sys\n",
"\n",
"PROJECT_ID = \"\" # @param {type:\"string\"}\n",
"LOCATION = \"us-central1\" # @param {type:\"string\"}\n",
"\n",
"# if not running on Colab, try to get the PROJECT_ID automatically\n",
"if \"google.colab\" not in sys.modules:\n",
" import subprocess\n",
"\n",
" PROJECT_ID = subprocess.check_output(\n",
" [\"gcloud\", \"config\", \"get-value\", \"project\"], text=True\n",
" ).strip()\n",
"\n",
"print(f\"Your project ID is: {PROJECT_ID}\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "9aa0339469d7"
},
"outputs": [],
"source": [
"import sys\n",
"\n",
"# Initialize Vertex AI\n",
"import vertexai\n",
"\n",
"vertexai.init(project=PROJECT_ID, location=LOCATION)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "BuQwwRiniVFG"
},
"source": [
"### Import libraries\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "rtMowvm-yQ97"
},
"outputs": [],
"source": [
"from typing import Any\n",
"\n",
"from PIL import Image as PILImage # Explicit import for clarity\n",
"import numpy as np\n",
"import pandas as pd\n",
"import vertexai\n",
"from vertexai.language_models import TextEmbeddingInput, TextEmbeddingModel\n",
"from vertexai.vision_models import Image as VMImage\n",
"from vertexai.vision_models import MultiModalEmbeddingModel, MultiModalEmbeddingResponse\n",
"from vertexai.vision_models import Video as VMVideo\n",
"from vertexai.vision_models import VideoSegmentConfig\n",
"\n",
"pd.options.mode.chained_assignment = None # default='warn'"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "r-TX_R_xh2rM"
},
"source": [
"### Load Vertex AI Text and Multimodal Embeddings\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "SvMwSRJJh2rM"
},
"outputs": [],
"source": [
"mm_embedding_model = MultiModalEmbeddingModel.from_pretrained(\"multimodalembedding\")\n",
"text_embedding_model = TextEmbeddingModel.from_pretrained(\"text-embedding-005\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "UN-Srse-tt7k"
},
"source": [
"## Basics of Vertex AI embeddings API"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "TQqqctKSyjfz"
},
"source": [
"## Text Embedding"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "DLfNXQLMyj43"
},
"source": [
"Text embeddings are a dense, often low-dimensional, vector representation of a piece of content such that, if two pieces of content are semantically similar, their respective embeddings are located near each other in the embedding vector space. This representation can be used to solve common NLP tasks, such as:\n",
"\n",
"* **Semantic search**: Search text ranked by semantic similarity.\n",
"* **Recommendation**: Return items with text attributes similar to the given text.\n",
"* **Classification**: Return the class of items whose text attributes are similar to the given text.\n",
"* **Clustering**: Cluster items whose text attributes are similar to the given text.\n",
"* **Outlier Detection**: Return items where text attributes are least related to the given text.\n",
"\n",
"Please refer to the [text embedding model documentation](https://cloud.google.com/vertex-ai/docs/generative-ai/embeddings/get-text-embeddings) for more information."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "v28L_YJRzcEK"
},
"outputs": [],
"source": [
"def embed_text(\n",
" texts: list[str] = [\"banana muffins? \", \"banana bread? banana muffins?\"],\n",
" model: str = text_embedding_model,\n",
") -> list[list[float]]:\n",
" \"\"\"Embeds texts with a pre-trained, foundational model.\"\"\"\n",
" # model = TextEmbeddingModel.from_pretrained(model_name)\n",
" inputs = [TextEmbeddingInput(text) for text in texts]\n",
" embeddings = model.get_embeddings(inputs)\n",
" return [embedding.values for embedding in embeddings]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "beaMkDH9zlr2"
},
"outputs": [],
"source": [
"tex_embedding = embed_text(texts=[\"What is life?\"])\n",
"print(\"length of embedding: \", len(tex_embedding[0]))\n",
"print(\"First five vectors are: \", tex_embedding[0][:5])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "oXC0cEjDywIM"
},
"source": [
"#### Embeddings and Pandas DataFrames"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "oug-MkjFywzc"
},
"source": [
"If your text is stored in a column of a DataFrame, you can create a new column with the embeddings with the example below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "trpS0J6ByNd0"
},
"outputs": [],
"source": [
"import pandas as pd\n",
"\n",
"text = [\n",
" \"i really enjoyed the movie last night\",\n",
" \"so many amazing cinematic scenes yesterday\",\n",
" \"had a great time writing my Python scripts a few days ago\",\n",
" \"huge sense of relief when my .py script finally ran without error\",\n",
" \"O Romeo, Romeo, wherefore art thou Romeo?\",\n",
"]\n",
"\n",
"df = pd.DataFrame(text, columns=[\"text\"])\n",
"df"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "luwdn0qA0QZN"
},
"source": [
"Create a new column, `embeddings`, using the [apply](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.apply.html) function in pandas with the embeddings model."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "etrempeSyQ9V"
},
"outputs": [],
"source": [
"df[\"embeddings\"] = df.apply(lambda x: embed_text([x.text])[0], axis=1)\n",
"df"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "3_rtywdA0cv6"
},
"source": [
"#### Comparing similarity of text examples using cosine similarity"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "PXMu9UYs0Z8S"
},
"source": [
"By converting text into embeddings, you can compute similarity scores. There are many ways to compute similarity scores, and one common technique is using [cosine similarity](https://en.wikipedia.org/wiki/Cosine_similarity).\n",
"\n",
"In the example from above, two of the sentences in the `text` column relate to enjoying a _movie_, and the other two relates to enjoying _coding_. Cosine similarity scores should be higher (closer to 1.0) when doing pairwise comparisons between semantically-related sentences, and scores should be lower between semantically-different sentences.\n",
"\n",
"The DataFrame output below shows the resulting cosine similarity scores between the embeddings:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "BXtUBuV9y4oX"
},
"outputs": [],
"source": [
"from sklearn.metrics.pairwise import cosine_similarity\n",
"\n",
"cos_sim_array = cosine_similarity(list(df.embeddings.values))\n",
"\n",
"# display as DataFrame\n",
"df = pd.DataFrame(cos_sim_array, index=text, columns=text)\n",
"df"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "BFE6uErz0gGe"
},
"source": [
"To make this easier to understand, you can use a heatmap. Naturally, text is most similar when they are identical (score of 1.0). The next highest scores are when sentences are semantically similar. The lowest scores are when sentences are quite different in meaning."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "6E4cfugj0gmC"
},
"outputs": [],
"source": [
"import seaborn as sns\n",
"\n",
"ax = sns.heatmap(df, annot=True, cmap=\"crest\")\n",
"ax.xaxis.tick_top()\n",
"ax.set_xticklabels(text, rotation=90)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "qPnk16P213qW"
},
"source": [
"## Multimodal Embedding API"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "iF0NNyDv13fX"
},
"source": [
"The [multimodal embeddings](https://cloud.google.com/vertex-ai/generative-ai/docs/embeddings/get-multimodal-embeddings) model generates [ 128, 256, 512, and 1408 (default) ] -dimension vectors based on the input you provide, which can include a combination of image, text, and video data. The embedding vectors can then be used for subsequent tasks like image classification or video content moderation.\n",
"\n",
"The image embedding vector and text embedding vector are in the same semantic space with the same dimensionality. Consequently, these vectors can be used interchangeably for use cases like searching image by text, or searching video by image.\n",
"\n",
"For text-only embedding use cases, we recommend using the Vertex AI text-embeddings API instead demonstrate above.\n",
"\n",
"**Use cases**\n",
"\n",
"**Image and text:**\n",
"\n",
"\n",
"* Image classification: Takes an image as input and predicts one or more classes (labels).\n",
"* Image search: Search relevant or similar images.\n",
"* Recommendations: Generate product or ad recommendations based on images.\n",
"\n",
"\n",
"\n",
"**Image, text, and video:**\n",
"\n",
"* Recommendations: Generate product or advertisement recommendations based on videos (similarity search).\n",
"* Video content search\n",
" * Using semantic search: Take a text as an input, and return a set of ranked frames matching the query.\n",
"* Using similarity search:\n",
" * Take a video as an input, and return a set of videos matching the query.\n",
" * Take an image as an input, and return a set of videos matching the query.\n",
"* Video classification: Takes a video as input and predicts one or more classes.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "olQ6tojAQR5V"
},
"outputs": [],
"source": [
"def get_image_video_text_embeddings(\n",
" image_path: str | None = None,\n",
" video_path: str | None = None,\n",
" contextual_text: str | None = None,\n",
" dimension: int | None = 1408,\n",
" video_segment_config: VideoSegmentConfig | None = None,\n",
" debug: bool = False,\n",
") -> MultiModalEmbeddingResponse:\n",
" \"\"\"Generates multimodal embeddings from image, video, and text.\n",
"\n",
" Args:\n",
" image_path: Path to image (local or Google Cloud Storage).\n",
" video_path: Path to video (local or Google Cloud Storage).\n",
" contextual_text: Text to generate embeddings for. Max: 32 tokens (~32 words).\n",
" dimension: Dimension of the returned embeddings (128, 256, 512, or 1408).\n",
" video_segment_config: Defines specific video segments for embedding generation.\n",
" debug: If True, print debugging information.\n",
"\n",
" Returns:\n",
" MultiModalEmbeddingResponse: The generated embeddings.\n",
"\n",
" Raises:\n",
" ValueError: If neither image_path, video_path, nor contextual_text is provided.\n",
" \"\"\"\n",
"\n",
" # Input validation\n",
" if not any([image_path, video_path, contextual_text]):\n",
" raise ValueError(\n",
" \"At least one of image_path, video_path, or contextual_text must be provided.\"\n",
" )\n",
"\n",
" image = VMImage.load_from_file(image_path) if image_path else None\n",
" video = VMVideo.load_from_file(video_path) if video_path else None\n",
"\n",
" embeddings = mm_embedding_model.get_embeddings(\n",
" image=image,\n",
" video=video,\n",
" video_segment_config=video_segment_config,\n",
" contextual_text=contextual_text,\n",
" dimension=dimension,\n",
" )\n",
"\n",
" # Prepare result dictionary for better organization\n",
" result = {}\n",
"\n",
" if image_path:\n",
" if debug:\n",
" print(\n",
" f\"\\n\\nImage Embedding (first five):\\n{embeddings.image_embedding[:5]}\"\n",
" )\n",
" print(f\"Dimension of Image Embedding: {len(embeddings.image_embedding)}\")\n",
" result[\"image_embedding\"] = embeddings.image_embedding\n",
"\n",
" if video_path:\n",
" if debug:\n",
" print(\"Video Embeddings:\")\n",
" video_embedding_list = [\n",
" {\n",
" \"start_offset_sec\": video_embedding.start_offset_sec,\n",
" \"end_offset_sec\": video_embedding.end_offset_sec,\n",
" \"embedding\": video_embedding.embedding,\n",
" }\n",
" for video_embedding in embeddings.video_embeddings\n",
" ]\n",
" result[\"video_embeddings\"] = video_embedding_list\n",
"\n",
" if debug:\n",
" for embedding in video_embedding_list:\n",
" print(\n",
" f\"\\nVideo Segment (in seconds): {embedding['start_offset_sec']} - {embedding['end_offset_sec']}\"\n",
" )\n",
" print(f\"Embedding (first five): {embedding['embedding'][:5]}\")\n",
" print(f\"Dimension of Video Embedding: {len(embedding['embedding'])}\")\n",
"\n",
" if contextual_text:\n",
" if debug:\n",
" print(f\"\\n\\nText Embedding (first five):\\n{embeddings.text_embedding[:5]}\")\n",
" print(f\"Dimension of Text Embedding: {len(embeddings.text_embedding)}\")\n",
" result[\"text_embedding\"] = embeddings.text_embedding\n",
"\n",
" return result"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "10kzx4YoVjMU"
},
"outputs": [],
"source": [
"# Image embeddings with default 1408 dimension\n",
"result = get_image_video_text_embeddings(\n",
" image_path=\"gs://github-repo/embeddings/getting_started_embeddings/gms_images/GGOEACBA104999.jpg\",\n",
" debug=True,\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "eRYoTJqwwu9D"
},
"outputs": [],
"source": [
"# Image embeddings with 256 dimension each\n",
"\n",
"result = get_image_video_text_embeddings(\n",
" image_path=\"gs://github-repo/embeddings/getting_started_embeddings/gms_images/GGOEAFKA194799.jpg\",\n",
" dimension=256, # Available values: 128, 256, 512, and 1408 (default)\n",
" debug=True,\n",
") # printing first 10 vectors only"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "QeGOaYxGwtdp"
},
"outputs": [],
"source": [
"# Video embeddings with 1408 dimension # Video embedding only supports 1408\n",
"\n",
"result = get_image_video_text_embeddings(\n",
" video_path=\"gs://github-repo/embeddings/getting_started_embeddings/UCF-101-subset/BrushingTeeth/v_BrushingTeeth_g01_c02.mp4\",\n",
" debug=True,\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "IOa8OrJpyYlK"
},
"outputs": [],
"source": [
"# Video embeddings with 1408 dimension and Video Segment. # Video embedding only supports 1408\n",
"\n",
"\n",
"result = get_image_video_text_embeddings(\n",
" video_path=\"gs://github-repo/embeddings/getting_started_embeddings/Google's newest and most capable AI Gemini.mp4\",\n",
" video_segment_config=VideoSegmentConfig(\n",
" start_offset_sec=0, end_offset_sec=120, interval_sec=60\n",
" ),\n",
" debug=True,\n",
") # printing first 10 vectors only"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "wnZmYUhkRf0u"
},
"source": [
"## Use-case: Building simple search with embeddings"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "2NP6ovQVTeFV"
},
"source": [
"### Build embeddings for data from scratch"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "hlOmaXeEXV9p"
},
"source": [
"#### Video Embeddings"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "r17fSDV8Uy-p"
},
"outputs": [],
"source": [
"data_url = \"https://storage.googleapis.com/github-repo/embeddings/getting_started_embeddings/video_data_without_embeddings.csv\"\n",
"video_data_without_embeddings = pd.read_csv(data_url)\n",
"video_data_without_embeddings.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "El2wJCTUQ5ux"
},
"outputs": [],
"source": [
"# %%time ~3 min\n",
"# video_data_without_embeddings = pd.read_csv(data_url)\n",
"# # Create new dataframe to store embeddings\n",
"# video_data_with_embeddings = video_data_without_embeddings.copy()\n",
"\n",
"# # Get Video Embeddings\n",
"# video_data_with_embeddings[\"video_embeddings\"] = (\n",
"# video_data_without_embeddings[\"gcs_path\"]\n",
"# .apply(\n",
"# lambda x: get_image_video_text_embeddings(video_path=x)['video_embeddings'][0]['embedding']\n",
"# )\n",
"# )\n",
"\n",
"# video_data_with_embeddings.head()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "xY3eurefXZ1E"
},
"source": [
"#### Image and Text Embeddings"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "dzAteOhSSr8K"
},
"outputs": [],
"source": [
"data_url = \"https://storage.googleapis.com/github-repo/embeddings/getting_started_embeddings/image_data_without_embeddings.csv\"\n",
"image_data_without_embeddings = pd.read_csv(data_url)\n",
"image_data_without_embeddings.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "LExwGZuKSEbZ"
},
"outputs": [],
"source": [
"# %%time ~5min\n",
"\n",
"# # Create new dataframe to store embeddings\n",
"# image_data_with_embeddings = image_data_without_embeddings.copy()\n",
"\n",
"# # Combining all the text metadata in a single column.\n",
"# image_data_with_embeddings[\"combined_text\"] = (\n",
"# image_data_with_embeddings[\"title\"].fillna(\"\")\n",
"# + \" \"\n",
"# + image_data_with_embeddings[\"keywords\"].fillna(\"\")\n",
"# + \" \"\n",
"# + image_data_with_embeddings[\"metadescription\"].fillna(\"\")\n",
"# )\n",
"\n",
"# # Get Image and Text Embeddings\n",
"\n",
"# # Taking default 1408 dimension\n",
"# image_data_with_embeddings[\"image_embeddings\"] = image_data_with_embeddings[\n",
"# \"gcs_path\"\n",
"# ].apply(lambda x: get_image_video_text_embeddings(image_path=x)[\"image_embedding\"])\n",
"# # Taking default 768 dimension\n",
"# image_data_with_embeddings[\"text_embeddings\"] = image_data_with_embeddings[\n",
"# \"combined_text\"\n",
"# ].apply(lambda x: embed_text([x])[0])\n",
"\n",
"# image_data_with_embeddings.head()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "H1TyK-ENVlHf"
},
"source": [
"## Load pre-computed embeddings"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "nigd4xO7Vow5"
},
"outputs": [],
"source": [
"# Comment this cell, if you are computing embeddings from scratch.\n",
"\n",
"image_data_with_embeddings = pd.read_csv(\n",
" \"https://storage.googleapis.com/github-repo/embeddings/getting_started_embeddings/image_data_with_embeddings.csv\"\n",
") # dimensions; image = 1408, text = 768\n",
"video_data_with_embeddings = pd.read_csv(\n",
" \"https://storage.googleapis.com/github-repo/embeddings/getting_started_embeddings/video_data_with_embeddings.csv\"\n",
") # dimensions; video = 1408"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "KA3j0sPYV7TP"
},
"outputs": [],
"source": [
"image_data_with_embeddings.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "T3aF8-A0V9mF"
},
"outputs": [],
"source": [
"video_data_with_embeddings.head()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "uzlJc6V9A_R5"
},
"source": [
"## Use-case - Images & text"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "73CFiID6WNo8"
},
"source": [
"### Find product based on text search query"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "6mxZkwefyAzD"
},
"outputs": [],
"source": [
"from IPython.display import Image as ImageByte\n",
"from IPython.display import display\n",
"\n",
"\n",
"def get_url_from_gcs(gcs_uri: str) -> str:\n",
" \"\"\"Converts a Google Cloud Storage (GCS) URI to a publicly accessible URL.\n",
"\n",
" Args:\n",
" gcs_uri: The GCS URI in the format gs://bucket-name/object-name.\n",
"\n",
" Returns:\n",
" The corresponding public URL for the object.\n",
" \"\"\"\n",
" return gcs_uri.replace(\"gs://\", \"https://storage.googleapis.com/\").replace(\n",
" \" \", \"%20\"\n",
" )\n",
"\n",
"\n",
"def print_shortlisted_products(\n",
" shortlisted_products: dict | Any, display_flag: bool = False\n",
") -> None:\n",
" \"\"\"Prints information about shortlisted products, optionally displaying images.\n",
"\n",
" Args:\n",
" shortlisted_products: A dictionary-like object containing product data with 'score' and 'gcs_path' keys.\n",
" display_flag: If True, displays images of the products using IPython.\n",
" \"\"\"\n",
" print(\"Similar product identified ---- \\n\")\n",
"\n",
" for (\n",
" index,\n",
" product,\n",
" ) in shortlisted_products.iterrows(): # Iterate directly over rows for clarity\n",
" score = product[\"score\"]\n",
" gcs_path = product[\"gcs_path\"]\n",
" url = get_url_from_gcs(gcs_path)\n",
"\n",
" print(f\"Product {index + 1}: Confidence Score: {score}\")\n",
" print(url)\n",
"\n",
" if display_flag:\n",
" display(ImageByte(url=url)) # Simplified image display\n",
" print() # Add an empty line for visual separation"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "GvtbNS8MH6B5"
},
"source": [
"**Cosine Similarity: A Measure of Orientation, Not Magnitude**\n",
"\n",
"Cosine similarity is a mathematical tool to gauge the similarity between two vectors (like points in space). Think of vectors as arrows:\n",
"* **Direction:** Each vector points in a particular direction.\n",
"* **Length:** Each vector has a certain length (magnitude).\n",
"\n",
"\n",
"Cosine similarity focuses on the angle between two vectors, ignoring their lengths. If two vectors point in almost the same direction, they are considered highly similar (cosine similarity close to 1). If they're at a right angle, they're completely dissimilar (cosine similarity of 0). Opposite directions give a similarity of -1.\n",
"\n",
"Read more about [cosine similarity](https://en.wikipedia.org/wiki/Cosine_similarity)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "B9iueDzaIOyO"
},
"source": [
"**Embeddings: Transforming Data into Vectors**\n",
"\n",
"In machine learning, an embedding is a way to represent complex data (like text, images, or videos) as vectors. This allows us to apply mathematical operations like cosine similarity. For example:\n",
"\n",
"* **Word Embeddings:** Words with similar meanings have vectors that point in similar directions.\n",
"* **Image Embeddings:** Images with similar content (e.g., two pictures of cats) have vectors with a small angle between them.\n",
"* **Video Embeddings:** Videos of the same event or with similar themes have similar vector representations.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "vEQ7SK4VIZe7"
},
"source": [
"**Other Distance Metrics for Vectors**\n",
"\n",
"While cosine similarity is popular, it's not the only way to measure distance between vectors. Here are a few others:\n",
"\n",
"* **Euclidean Distance:** The straight-line distance between two points. Sensitive to differences in magnitude.\n",
"* **Manhattan Distance:** The distance between two points if you can only move along a grid (like city blocks).\n",
"* **Hamming Distance:** The number of positions at which two vectors differ (often used for binary data).\n",
"\n",
"**Choosing the Right Distance Metric**\n",
"The best distance metric depends on your specific application. Cosine similarity is often preferred when you care more about the relationship between items (e.g., meaning of words, content of images) rather than their absolute magnitude.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "SIiC_5JxWRMw"
},
"outputs": [],
"source": [
"search_query = \"I am looking for something related to dinosaurs theme\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "96XUS3lDYikY"
},
"outputs": [],
"source": [
"# Steps to get similar products\n",
"\n",
"# Step 1 - Convert 'search_query' to embeddings\n",
"search_query_embedding = embed_text([search_query])[0]\n",
"\n",
"# Step 2 - Find cosine similarity (or simply np.dot) of search_query_embedding and image_data_with_embeddings['text_embeddings']\n",
"cosine_scores = image_data_with_embeddings[\"text_embeddings\"].apply(\n",
" lambda x: round(np.dot(eval(x), search_query_embedding), 2)\n",
") # eval is used to convert string of list to list\n",
"\n",
"# Step 3 - Sort the cosine score and pick the top 3 results\n",
"top_3_indices = cosine_scores.nlargest(3).index.tolist()\n",
"top_n_cosine_values = cosine_scores.nlargest(3).values.tolist()\n",
"\n",
"# Step 4 - Filter image_data_with_embeddings with the shortlisted index and add score\n",
"shortlisted_products = image_data_with_embeddings.iloc[top_3_indices]\n",
"shortlisted_products.loc[:, \"score\"] = top_n_cosine_values\n",
"\n",
"# Step 5 - Display the shortlisted products\n",
"print_shortlisted_products(\n",
" shortlisted_products\n",
") # pass display_flag=True to display the images"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "jwf5m588zs33"
},
"outputs": [],
"source": [
"def get_similar_products_from_text_query(\n",
" search_query: str,\n",
" top_n: int = 3,\n",
" threshold: float = 0.6,\n",
" embeddings_data: pd.DataFrame = image_data_with_embeddings,\n",
") -> pd.DataFrame | None:\n",
" \"\"\"\n",
" Retrieves the most similar products to a given text query based on embeddings.\n",
"\n",
" Args:\n",
" search_query: The text query to find similar products for.\n",
" top_n: The maximum number of similar products to return.\n",
" threshold: The minimum cosine similarity score for a product to be considered similar.\n",
" embeddings_data: A DataFrame containing text embeddings for products (assumes a column named 'text_embeddings').\n",
"\n",
" Returns:\n",
" A DataFrame with the top_n similar products and their scores, or None if none meet the threshold.\n",
" \"\"\"\n",
"\n",
" # Step 1: Embed the search query\n",
" search_query_embedding = embed_text([search_query])[\n",
" 0\n",
" ] # Assuming 'embed_text' is a function you have\n",
"\n",
" # Step 2: Calculate cosine similarities (optimize by avoiding apply and eval)\n",
" cosine_scores = image_data_with_embeddings[\"text_embeddings\"].apply(\n",
" lambda x: round(np.dot(eval(x), search_query_embedding), 2)\n",
" )\n",
"\n",
" # Step 3: Filter and sort scores\n",
" scores_above_threshold = cosine_scores[cosine_scores >= threshold]\n",
" top_n_indices = scores_above_threshold.nlargest(top_n).index.tolist()\n",
"\n",
" # Step 4: Handle cases with insufficient scores\n",
" if len(top_n_indices) < top_n:\n",
" print(f\"Warning: Only {len(top_n_indices)} scores meet the threshold.\")\n",
"\n",
" # Step 5: Get shortlisted products with scores (optimize by direct assignment)\n",
" if top_n_indices:\n",
" shortlisted_products = embeddings_data.iloc[top_n_indices].copy()\n",
" shortlisted_products[\"score\"] = scores_above_threshold.nlargest(\n",
" top_n\n",
" ).values.tolist()\n",
" else:\n",
" print(\"No scores meet the threshold. Consider lowering the threshold.\")\n",
" shortlisted_products = None\n",
"\n",
" return shortlisted_products"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "B3Dui6Y1gM4G"
},
"outputs": [],
"source": [
"search_query = \"Do you have socks in checkered patterns?\"\n",
"\n",
"shortlisted_products = get_similar_products_from_text_query(\n",
" search_query, top_n=3, threshold=0.7\n",
")\n",
"\n",
"print_shortlisted_products(shortlisted_products)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "WSdmrJ_gqUtQ"
},
"outputs": [],
"source": [
"search_query = \"I am looking for sweatshirt with google logo and probably should be in embroidered pattern\"\n",
"\n",
"shortlisted_products = get_similar_products_from_text_query(\n",
" search_query, top_n=3, threshold=0.6\n",
")\n",
"\n",
"print_shortlisted_products(shortlisted_products)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "dq8ZpN6BlrJC"
},
"source": [
"### Find Similar product based on images (selected product)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "TuQ9lehmkuly"
},
"outputs": [],
"source": [
"random_index = 130\n",
"liked_product = image_data_with_embeddings[\"gcs_path\"][random_index]\n",
"print(\"Liked Product ---\")\n",
"\n",
"\n",
"print(get_url_from_gcs(liked_product))\n",
"\n",
"# to display the image\n",
"# display(ImageByte(url=get_url_from_gcs(liked_product)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "qnWETYpRlxSO"
},
"outputs": [],
"source": [
"# Steps to get similar products\n",
"\n",
"# Step 1 - Convert 'liked_product' to embeddings\n",
"liked_product_embedding = get_image_video_text_embeddings(image_path=liked_product)[\n",
" \"image_embedding\"\n",
"]\n",
"\n",
"# Step 2 - Find cosine similarity (or simply np.dot) of liked_product_embedding and image_data_with_embeddings['image_embeddings']\n",
"cosine_scores = image_data_with_embeddings[\"image_embeddings\"].apply(\n",
" lambda x: round(np.dot(eval(x), liked_product_embedding), 2)\n",
") # eval is used to convert string of list to list\n",
"\n",
"\n",
"# Step 3 - Sort the cosine score, filter with threshold (matching should be less than 1.0 and greater than high value) and pick the top 2 results\n",
"threshold = 0.6\n",
"scores_above_threshold = cosine_scores[\n",
" (cosine_scores >= threshold) & (cosine_scores < 1.00)\n",
"]\n",
"top_2_indices = scores_above_threshold.nlargest(2).index.tolist()\n",
"top_2_cosine_values = scores_above_threshold.nlargest(2).values.tolist()\n",
"\n",
"# Step 4 - Filter image_data_with_embeddings with the shortlisted index\n",
"shortlisted_products = image_data_with_embeddings.iloc[top_2_indices]\n",
"shortlisted_products.loc[:, \"score\"] = top_2_cosine_values\n",
"\n",
"# Step 5 - Display the shortlisted product.\n",
"print_shortlisted_products(shortlisted_products)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "8gUufHrb0glL"
},
"outputs": [],
"source": [
"def get_similar_products_from_image_query(\n",
" liked_product: str | np.ndarray, top_n: int = 3, threshold: float = 0.6\n",
") -> pd.DataFrame | None:\n",
" \"\"\"\n",
" Retrieves similar products based on an image query.\n",
"\n",
" This function takes an image path or embedding of a \"liked\" product, compares it to\n",
" a dataset of product embeddings, and returns the top N most similar products\n",
" that exceed a specified similarity threshold.\n",
"\n",
" Args:\n",
" liked_product: Path to the image file of the liked product or its embedding.\n",
" top_n: The maximum number of similar products to return.\n",
" threshold: The minimum cosine similarity score for a product to be considered similar.\n",
"\n",
" Returns:\n",
" A pandas DataFrame containing the top N similar products and their scores,\n",
" or None if no products meet the threshold.\n",
" \"\"\"\n",
"\n",
" # Step 1: Ensure the `liked_product` is an embedding\n",
" if isinstance(liked_product, str):\n",
" liked_product_embedding = get_image_video_text_embeddings(\n",
" image_path=liked_product\n",
" )[\"image_embedding\"]\n",
" else:\n",
" liked_product_embedding = liked_product\n",
"\n",
" # Step 2: Calculate cosine similarities\n",
" # Convert embeddings to numpy arrays for efficient calculation if necessary\n",
" if isinstance(image_data_with_embeddings[\"image_embeddings\"].iloc[0], str):\n",
" image_data_with_embeddings[\"image_embeddings\"] = image_data_with_embeddings[\n",
" \"image_embeddings\"\n",
" ].apply(eval)\n",
" cosine_scores = image_data_with_embeddings[\"image_embeddings\"].apply(\n",
" lambda x: np.dot(x, liked_product_embedding)\n",
" )\n",
"\n",
" # Step 3: Filter and select top scores\n",
" scores_above_threshold = cosine_scores[\n",
" (cosine_scores >= threshold) & (cosine_scores < 1.0)\n",
" ]\n",
" top_n_indices = scores_above_threshold.nlargest(top_n).index.tolist()\n",
" top_n_cosine_values = scores_above_threshold.nlargest(top_n).values.tolist()\n",
"\n",
" # Step 4: Log insufficient scores (optional)\n",
" if len(top_n_indices) < top_n:\n",
" print(f\"Warning: Only {len(top_n_indices)} scores meet the threshold.\")\n",
"\n",
" # Step 5: Return results if scores are available\n",
" if top_n_indices:\n",
" shortlisted_products = image_data_with_embeddings.iloc[top_n_indices].copy()\n",
" shortlisted_products[\"score\"] = top_n_cosine_values\n",
" return shortlisted_products\n",
"\n",
" else:\n",
" print(\"No scores meet the threshold. Consider lowering the threshold.\")\n",
" return None"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "UEilR5BObZKb"
},
"outputs": [],
"source": [
"random_index = 9\n",
"liked_product = image_data_with_embeddings[\"gcs_path\"][random_index]\n",
"print(\"Liked Product ---\")\n",
"print(get_url_from_gcs(liked_product))\n",
"\n",
"# to display the image\n",
"# display(ImageByte(url=get_url_from_gcs(liked_product)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "AHQGSZh5pTaz"
},
"outputs": [],
"source": [
"# get recommendation for the liked product (image)\n",
"shortlisted_products = get_similar_products_from_image_query(\n",
" liked_product, top_n=3, threshold=0.6\n",
")\n",
"\n",
"print_shortlisted_products(shortlisted_products)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "wHX2qX9vcE-O"
},
"outputs": [],
"source": [
"random_index = 120\n",
"liked_product = image_data_with_embeddings[\"gcs_path\"][random_index]\n",
"print(\"Liked Product ---\")\n",
"\n",
"print(get_url_from_gcs(liked_product))\n",
"\n",
"# to display the image\n",
"# display(ImageByte(url=get_url_from_gcs(liked_product)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "KCVJ_vbkcIGW"
},
"outputs": [],
"source": [
"# get recommendation for the liked product (image)\n",
"shortlisted_products = get_similar_products_from_image_query(\n",
" liked_product, top_n=3, threshold=0.6\n",
")\n",
"\n",
"print_shortlisted_products(shortlisted_products)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "btCIJCh2OnSP"
},
"source": [
"### Find Similar videos"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "6EpPyLjh1Kx0"
},
"outputs": [],
"source": [
"def display_video_gcs(\n",
" gcs_uri: str | None = None, public_gcs_url: str | None = None\n",
") -> None:\n",
" \"\"\"Displays a video hosted on Google Cloud Storage (GCS) in a Jupyter Notebook.\n",
"\n",
" Args:\n",
" gcs_uri: The GCS URI of the video.\n",
" public_gcs_url: The public URL of the video, if available. If not provided and\n",
" `gcs_uri` is given, the function will attempt to generate the public URL.\n",
"\n",
" Raises:\n",
" ValueError: If neither `gcs_uri` nor `public_gcs_url` is provided.\n",
" \"\"\"\n",
" if not gcs_uri and not public_gcs_url:\n",
" raise ValueError(\"Either gcs_uri or public_gcs_url must be provided.\")\n",
"\n",
" if gcs_uri and not public_gcs_url:\n",
" public_gcs_url = get_url_from_gcs(\n",
" gcs_uri\n",
" ) # Assuming you have a helper function for this\n",
"\n",
" html_code = f\"\"\"\n",
" <video width=\"640\" height=\"480\" controls>\n",
" <source src=\"{public_gcs_url}\" type=\"video/mp4\">\n",
" Your browser does not support the video tag.\n",
" </video>\n",
" \"\"\"\n",
" display(HTML(html_code))\n",
"\n",
"\n",
"def print_shortlisted_video(\n",
" shortlisted_videos: list[dict], display_flag: bool = False\n",
") -> None:\n",
" \"\"\"Prints information about shortlisted videos and optionally displays them.\n",
"\n",
" Args:\n",
" shortlisted_videos: A list of dictionaries where each dictionary represents a video\n",
" with keys 'score' (float) and 'gcs_path' (str).\n",
" display_flag: If True, displays each video in the notebook.\n",
" \"\"\"\n",
" print(\"Similar videos identified ---- \\n\")\n",
"\n",
" for i in range(len(shortlisted_videos)):\n",
" print(f\"Video {i+1}: Confidence Score: {shortlisted_products['score'].iloc[i]}\")\n",
"\n",
" url = get_url_from_gcs(shortlisted_videos[\"gcs_path\"].values[i])\n",
" print(url)\n",
" if display_flag:\n",
" display_video_gcs(public_gcs_url=url)\n",
" # IPython.display.display(load_image_from_url(url))\n",
" print() # Add an empty line for visual separation"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "eqG-qUNAeEvV"
},
"outputs": [],
"source": [
"from IPython.display import HTML\n",
"\n",
"random_index = 10\n",
"liked_video = video_data_with_embeddings[\"gcs_path\"][random_index]\n",
"public_gcs_url = get_url_from_gcs(video_data_with_embeddings[\"gcs_path\"][1])\n",
"\n",
"print(public_gcs_url)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "utdlMOESZ0MY"
},
"outputs": [],
"source": [
"# Steps to get similar video\n",
"\n",
"# Step 1 - Convert 'liked_video' to embeddings\n",
"liked_video_embedding = get_image_video_text_embeddings(video_path=liked_video)[\n",
" \"video_embeddings\"\n",
"][0][\"embedding\"]\n",
"\n",
"\n",
"# Step 2 - Find cosine similarity (or simply np.dot) of liked_video_embedding and video_data_with_embeddings['video_embeddings']\n",
"cosine_scores = video_data_with_embeddings[\"video_embeddings\"].apply(\n",
" lambda x: round(np.dot(eval(x), liked_video_embedding), 2)\n",
") # eval is used to convert string of list to list\n",
"\n",
"\n",
"# Step 3 - Sort the cosine score, filter with threshold (matching should be less than 1.0 and greater than high value) and pick the top 2 results\n",
"threshold = 0.6\n",
"scores_above_threshold = cosine_scores[\n",
" (cosine_scores >= threshold) & (cosine_scores < 1.00)\n",
"]\n",
"top_2_indices = scores_above_threshold.nlargest(2).index.tolist()\n",
"top_2_cosine_values = scores_above_threshold.nlargest(2).values.tolist()\n",
"\n",
"# Step 4 - Filter video_data_with_embeddings with the shortlisted index\n",
"shortlisted_videos = video_data_with_embeddings.iloc[top_2_indices]\n",
"shortlisted_videos.loc[:, \"score\"] = top_2_cosine_values\n",
"\n",
"# Step 5 - Display the shortlisted video.\n",
"print_shortlisted_video(shortlisted_videos) # display_flag=True"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "R5Dzahkj3ar-"
},
"outputs": [],
"source": [
"def get_similar_videos_from_video_query(\n",
" liked_video: str, top_n: int = 3, threshold: float = 0.6\n",
") -> pd.DataFrame:\n",
" \"\"\"\n",
" Retrieves similar videos to a given 'liked_video' using embeddings and cosine similarity.\n",
"\n",
" Args:\n",
" liked_video: The path to the video to find similar videos for.\n",
" top_n: The maximum number of similar videos to return.\n",
" threshold: The minimum cosine similarity score for a video to be considered similar.\n",
"\n",
" Returns:\n",
" A pandas DataFrame containing the shortlisted videos with their similarity scores.\n",
" \"\"\"\n",
"\n",
" # Step 1: Get the embeddings for the 'liked_video'\n",
" liked_video_embeddings = get_image_video_text_embeddings(video_path=liked_video)[\n",
" \"video_embeddings\"\n",
" ][0][\"embedding\"]\n",
"\n",
" # Ensure video_data_with_embeddings is available (you might need to load or define it)\n",
" if \"video_data_with_embeddings\" not in globals():\n",
" raise ValueError(\"video_data_with_embeddings DataFrame is not defined.\")\n",
"\n",
" # Step 2: Calculate cosine similarities with pre-loaded video embeddings\n",
" cosine_scores = video_data_with_embeddings[\"video_embeddings\"].apply(\n",
" lambda x: round(\n",
" np.dot(eval(x), liked_video_embeddings), 2\n",
" ) # Safely convert embeddings to arrays\n",
" )\n",
"\n",
" # Step 3: Filter and sort based on threshold and top_n\n",
" scores_above_threshold = cosine_scores[\n",
" (cosine_scores >= threshold) & (cosine_scores < 1.00)\n",
" ]\n",
" top_indices = scores_above_threshold.nlargest(top_n).index.tolist()\n",
" top_cosine_values = scores_above_threshold.nlargest(top_n).values.tolist()\n",
"\n",
" # Step 4: Get the shortlisted videos with scores\n",
" shortlisted_videos = video_data_with_embeddings.iloc[top_indices].copy()\n",
" shortlisted_videos[\"score\"] = top_cosine_values\n",
"\n",
" return shortlisted_videos"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "eIzf9zOkmo75"
},
"outputs": [],
"source": [
"random_index = 24\n",
"liked_video = video_data_with_embeddings[\"gcs_path\"][random_index]\n",
"public_gcs_url = get_url_from_gcs(video_data_with_embeddings[\"gcs_path\"][1])\n",
"\n",
"print(public_gcs_url)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ab9XUEBrmMxf"
},
"outputs": [],
"source": [
"shortlisted_videos = get_similar_videos_from_video_query(\n",
" liked_video, top_n=3, threshold=0.6\n",
")\n",
"print_shortlisted_video(shortlisted_videos)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "IddiO0T-wdno"
},
"source": [
"Next in the series:\n",
"\n",
"- Learn how to store the vectors (embeddings) into Vertex Vector Store: [Notebook](https://github.com/lavinigam-gcp/generative-ai/blob/main/embeddings/vector-search-quickstart.ipynb)\n",
"\n",
"- Learn how to tune the embeddings with your own data: [Notebook](https://github.com/lavinigam-gcp/generative-ai/blob/main/embeddings/intro_embeddings_tuning.ipynb)\n",
"\n",
"- Learn how to use embeddings to do Text RAG and Multimodal RAG: [Notebook](https://github.com/lavinigam-gcp/generative-ai/blob/main/gemini/use-cases/retrieval-augmented-generation/intro_multimodal_rag.ipynb)"
]
}
],
"metadata": {
"colab": {
"name": "intro_Vertex_AI_embeddings.ipynb",
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 0
}