workshops/rag-ops/2.1_mvp_data_processing.ipynb (996 lines of code) (raw):
{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "-PKa6W4wdPWr"
},
"outputs": [],
"source": [
"# Copyright 2024 Google LLC\n",
"#\n",
"# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
"# you may not use this file except in compliance with the License.\n",
"# You may obtain a copy of the License at\n",
"#\n",
"# https://www.apache.org/licenses/LICENSE-2.0\n",
"#\n",
"# Unless required by applicable law or agreed to in writing, software\n",
"# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
"# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
"# See the License for the specific language governing permissions and\n",
"# limitations under the License."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "idM_aIPheQDG"
},
"source": [
"# Stage 2: Building MVP: - 01 Data Processing\n",
"\n",
"\n",
"<table align=\"left\">\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://colab.research.google.com/github/GoogleCloudPlatform/generative-ai/blob/main/workshops/rag-ops/2.1_mvp_data_processing.ipynb\">\n",
" <img src=\"https://cloud.google.com/ml-engine/images/colab-logo-32px.png\" alt=\"Google Colaboratory logo\"><br> Open in Colab\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://console.cloud.google.com/vertex-ai/colab/import/https:%2F%2Fraw.githubusercontent.com%2FGoogleCloudPlatform%2Fgenerative-ai%2Fmain%2Fworkshops%2Frag-ops%2F2.1_mvp_data_processing.ipynb\">\n",
" <img width=\"32px\" src=\"https://lh3.googleusercontent.com/JmcxdQi-qOpctIvWKgPtrzZdJJK-J3sWE1RsfjZNwshCFgE_9fULcNpuXYTilIR2hjwN\" alt=\"Google Cloud Colab Enterprise logo\"><br> Open in Colab Enterprise\n",
" </a>\n",
" </td> \n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://console.cloud.google.com/vertex-ai/workbench/deploy-notebook?download_url=https://raw.githubusercontent.com/GoogleCloudPlatform/generative-ai/main/workshops/rag-ops/2.1_mvp_data_processing.ipynb\">\n",
" <img src=\"https://lh3.googleusercontent.com/UiNooY4LUgW_oTvpsNhPpQzsstV5W8F7rYgxgGBD85cWJoLmrOzhVs_ksK_vgx40SHs7jCqkTkCk=e14-rj-sc0xffffff-h130-w32\" alt=\"Vertex AI logo\"><br> Open in Workbench\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/rag-ops/2.1_mvp_data_processing.ipynb\">\n",
" <img src=\"https://cloud.google.com/ml-engine/images/github-logo-32px.png\" alt=\"GitHub logo\"><br> View on GitHub\n",
" </a>\n",
" </td>\n",
"</table>\n",
"\n",
"<div style=\"clear: both;\"></div>\n",
"\n",
"<b>Share to:</b>\n",
"\n",
"<a href=\"https://www.linkedin.com/sharing/share-offsite/?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/rag-ops/2.1_mvp_data_processing.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/8/81/LinkedIn_icon.svg\" alt=\"LinkedIn logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://bsky.app/intent/compose?text=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/rag-ops/2.1_mvp_data_processing.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/7/7a/Bluesky_Logo.svg\" alt=\"Bluesky logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://twitter.com/intent/tweet?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/rag-ops/2.1_mvp_data_processing.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/5/5a/X_icon_2.svg\" alt=\"X logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://reddit.com/submit?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/rag-ops/2.1_mvp_data_processing.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://redditinc.com/hubfs/Reddit%20Inc/Brand/Reddit_Logo.png\" alt=\"Reddit logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://www.facebook.com/sharer/sharer.php?u=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/rag-ops/2.1_mvp_data_processing.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/5/51/Facebook_f_logo_%282019%29.svg\" alt=\"Facebook logo\">\n",
"</a> "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "o0oOZgLKfhCi"
},
"source": [
"## Overview\n",
"\n",
"This notebook is the first in a series designed to guide you through building a Minimum Viable Product (MVP) for a Multimodal Retrieval Augmented Generation (RAG) system using the Gemini API in Vertex AI.\n",
"\n",
"**Here's what you'll achieve:**\n",
"\n",
"* **Process diverse data:** Extract information from PDFs, audio files, and video files. This includes text extraction from PDFs, and generating summaries and analyses from audio and video content.\n",
"* **Build from scratch:** Understand the core concepts of data processing for RAG without relying on third-party libraries like LangChain or LlamaIndex. This hands-on approach allows you to learn the fundamentals and customize your solution later.\n",
"* **Lay the foundation:** This notebook sets the stage for subsequent notebooks that cover data chunking, embeddings, retrieval, generation, and evaluation.\n",
"\n",
"By the end of this series, you'll have a working MVP and the knowledge to further develop and optimize your own multimodal RAG system.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "6KGP8kNhfklW"
},
"source": [
"## Getting Started"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "HGFDxQ7_flui"
},
"source": [
"### Install Vertex AI SDK for Python\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "YcWmeELUeTPq"
},
"outputs": [],
"source": [
"%pip install --upgrade --user --quiet google-cloud-aiplatform PyPDF2"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "SYYzbNlmfvKJ"
},
"source": [
"### Restart runtime\n",
"\n",
"To use the newly installed packages in this Jupyter runtime, you must restart the runtime. You can do this by running the cell below, which restarts the current kernel."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "icVKaoLAfw6c"
},
"outputs": [],
"source": [
"import sys\n",
"\n",
"if \"google.colab\" in sys.modules:\n",
" import IPython\n",
"\n",
" app = IPython.Application.instance()\n",
" app.kernel.do_shutdown(True)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "oZoekSN8fy2E"
},
"source": [
"<div class=\"alert alert-block alert-warning\">\n",
"<b>⚠️ The kernel is going to restart. Please wait until it is finished before continuing to the next step. ⚠️</b>\n",
"</div>\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "E4rlvfF1f1RA"
},
"source": [
"### Authenticate your notebook environment (Colab only)\n",
"\n",
"If you are running this notebook on Google Colab, run the cell below to authenticate your environment.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "XTaUAqKLf3N8"
},
"outputs": [],
"source": [
"import sys\n",
"\n",
"if \"google.colab\" in sys.modules:\n",
" from google.colab import auth\n",
"\n",
" auth.authenticate_user()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "iQJQgZKXf6Mx"
},
"source": [
"### Set Google Cloud project information, GCS Bucket and initialize Vertex AI SDK\n",
"\n",
"To get started using Vertex AI, you must have an existing Google Cloud project and [enable the Vertex AI API](https://console.cloud.google.com/flows/enableapi?apiid=aiplatform.googleapis.com).\n",
"\n",
"Learn more about [setting up a project and a development environment](https://cloud.google.com/vertex-ai/docs/start/cloud-environment)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "FqXU2Ptvf5LA"
},
"outputs": [],
"source": [
"import os\n",
"import sys\n",
"\n",
"from google.cloud import storage\n",
"import vertexai\n",
"\n",
"PROJECT_ID = \"[your-project-id]\" # @param {type:\"string\"}\n",
"LOCATION = \"us-central1\"\n",
"BUCKET_NAME = \"mlops-for-genai\"\n",
"\n",
"if PROJECT_ID == \"[your-project-id]\":\n",
" PROJECT_ID = str(os.environ.get(\"GOOGLE_CLOUD_PROJECT\"))\n",
"\n",
"if not PROJECT_ID or PROJECT_ID == \"[your-project-id]\" or PROJECT_ID == \"None\":\n",
" raise ValueError(\"Please set your PROJECT_ID\")\n",
"\n",
"\n",
"vertexai.init(project=PROJECT_ID, location=LOCATION)\n",
"\n",
"# Initialize cloud storage\n",
"storage_client = storage.Client(project=PROJECT_ID)\n",
"bucket = storage_client.bucket(BUCKET_NAME)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "6AbGiKORhxQ7"
},
"outputs": [],
"source": [
"# # Variables for data location. Do not change.\n",
"\n",
"PRODUCTION_DATA = \"multimodal-finanace-qa/data/unstructured/production/\"\n",
"PICKLE_FILE_NAME = \"data_extraction_dataframe.pkl\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "s9-h_WOcgAKX"
},
"source": [
"### Import libraries\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "OaW7NsbHgAoo"
},
"outputs": [],
"source": [
"import asyncio\n",
"import asyncio.locks\n",
"\n",
"# Library\n",
"from io import BytesIO\n",
"import os\n",
"import pickle\n",
"import time\n",
"\n",
"import PyPDF2\n",
"from google.cloud import storage\n",
"import pandas as pd\n",
"import psutil\n",
"from rich import print as rich_print\n",
"from rich.markdown import Markdown as rich_Markdown\n",
"from tenacity import retry, stop_after_attempt, wait_random_exponential\n",
"from vertexai.generative_models import (\n",
" GenerativeModel,\n",
" HarmBlockThreshold,\n",
" HarmCategory,\n",
" Part,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "A9hij3nhgDz8"
},
"source": [
"### Load the Gemini 2.0 models\n",
"\n",
"To learn more about all [Gemini API models on Vertex AI](https://cloud.google.com/vertex-ai/generative-ai/docs/learn/models#gemini-models).\n",
"\n",
"The Gemini model family has several model versions. You will start by using Gemini 2.0. Gemini 2.0 is a more lightweight, fast, and cost-efficient model. This makes it a great option for prototyping.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "7xvFkagTgHMc"
},
"outputs": [],
"source": [
"MODEL_ID_FLASH = \"gemini-2.0-flash\" # @param {type:\"string\"}\n",
"MODEL_ID_PRO = \"gemini-2.0-flash\" # @param {type:\"string\"}\n",
"\n",
"\n",
"gemini_15_flash = GenerativeModel(MODEL_ID_FLASH)\n",
"gemini_15_pro = GenerativeModel(MODEL_ID_PRO)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"id": "oS1ar31xYmkR"
},
"outputs": [],
"source": [
"# @title Gemini API Call Functions\n",
"\n",
"\n",
"def get_gemini_response(\n",
" model,\n",
" generation_config=None,\n",
" safety_settings=None,\n",
" uri_path=None,\n",
" mime_type=None,\n",
" prompt=None,\n",
"):\n",
" if not generation_config:\n",
" generation_config = {\n",
" \"max_output_tokens\": 8192,\n",
" \"temperature\": 1,\n",
" \"top_p\": 0.95,\n",
" }\n",
"\n",
" if not safety_settings:\n",
" safety_settings = {\n",
" HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_ONLY_HIGH,\n",
" HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_ONLY_HIGH,\n",
" HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_ONLY_HIGH,\n",
" HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_ONLY_HIGH,\n",
" }\n",
"\n",
" uri = \"gs://\" + uri_path\n",
" file = Part.from_uri(mime_type=mime_type, uri=uri)\n",
" responses = model.generate_content(\n",
" [file, prompt],\n",
" generation_config=generation_config,\n",
" safety_settings=safety_settings,\n",
" stream=True,\n",
" )\n",
" final_response = []\n",
" for response in responses:\n",
" try:\n",
" final_response.append(response.text)\n",
" except ValueError:\n",
" # print(\"Something is blocked...\")\n",
" final_response.append(\"blocked\")\n",
"\n",
" return \"\".join(final_response)\n",
"\n",
"\n",
"def get_load_dataframes_from_gcs():\n",
" gcs_path = \"multimodal-finanace-qa/data/structured/\" + PICKLE_FILE_NAME\n",
" # print(\"GCS PAth: \", gcs_path)\n",
" blob = bucket.blob(gcs_path)\n",
"\n",
" # Download the pickle file from GCS\n",
" blob.download_to_filename(f\"{PICKLE_FILE_NAME}\")\n",
"\n",
" # Load the pickle file into a list of dataframes\n",
" with open(f\"{PICKLE_FILE_NAME}\", \"rb\") as f:\n",
" dataframes = pickle.load(f)\n",
"\n",
" # Assign the dataframes to variables\n",
" extracted_text, audio_metadata_flash, video_metadata_flash = dataframes\n",
"\n",
" return extracted_text, audio_metadata_flash, video_metadata_flash"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "KKT4gg2ybwaR"
},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "20h6TWe0w8YY"
},
"source": [
"## Step 1: Data Processing"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Spw0nwSUb_et"
},
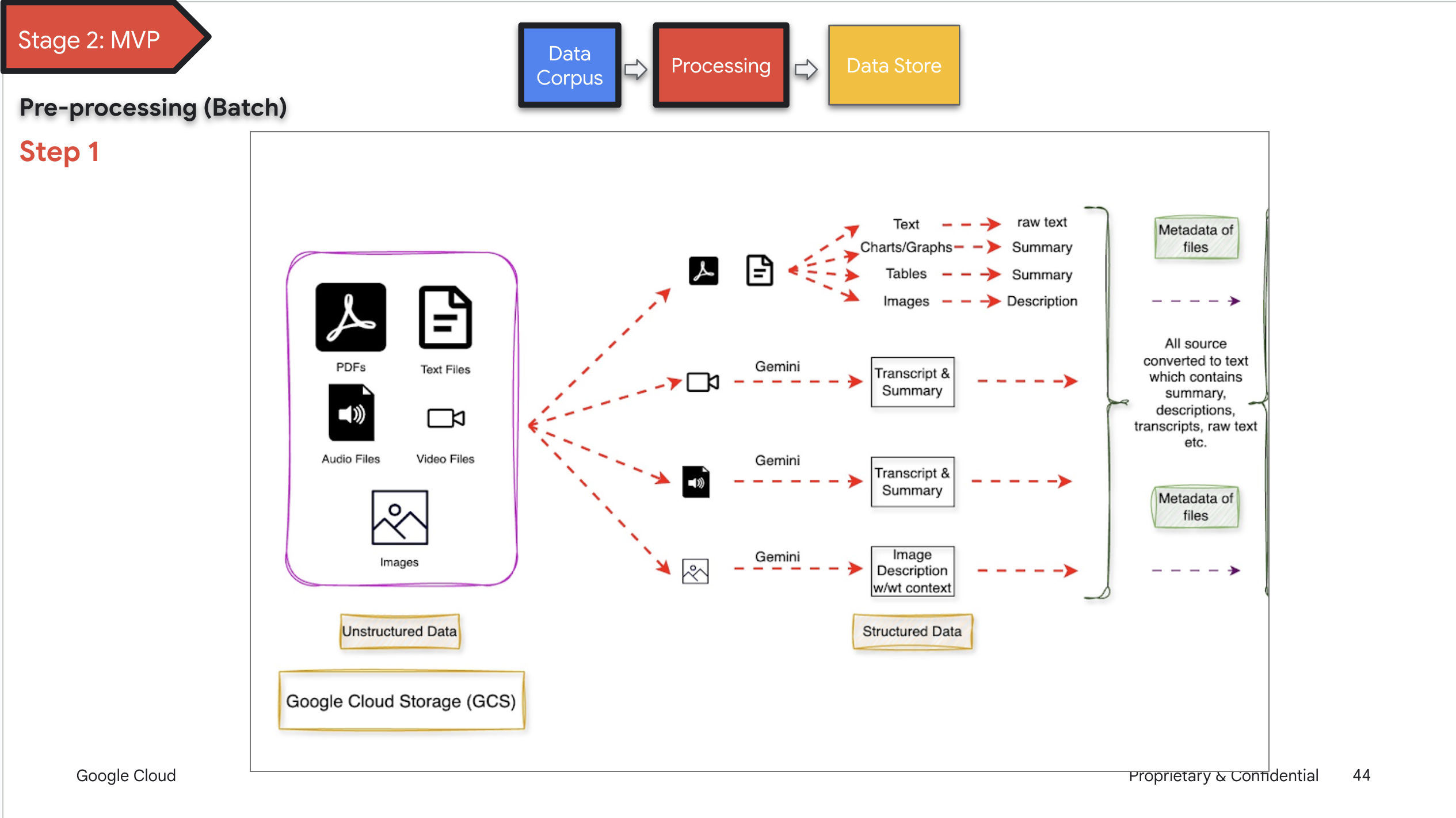
"source": [
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Jk5387FCjlAv"
},
"outputs": [],
"source": [
"# # [Optional]\n",
"# # You can load the dataframes from GCS which are pre-indexed to save time and cost\n",
"# # Uncomment the code below\n",
"\n",
"# extracted_text, audio_metadata_flash, video_metadata_flash = get_load_dataframes_from_gcs()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "B5_QeltmnjQi"
},
"source": [
"Or else you can continue to run the cells. Do note that it will take time to run through all the files."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "jXSJLRerP6n_"
},
"source": [
"### Text Extraction"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_V-AOTFyY0EE"
},
"source": [
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"id": "euCnxbAnV1qG"
},
"outputs": [],
"source": [
"# @title Helper Functions - Text Extraction from PDF\n",
"\n",
"\n",
"def get_text_from_pdf(bucket):\n",
" extracted_text = []\n",
" # Iterate over all blobs (files) in the bucket\n",
" for blob in bucket.list_blobs():\n",
" if blob.name.startswith(PRODUCTION_DATA):\n",
" if blob.name.lower().endswith(\".pdf\"): # Check if the file is a PDF\n",
" # Download the PDF to a BytesIO object\n",
" pdf_content = BytesIO(blob.download_as_bytes())\n",
" try:\n",
" # Process the PDF using PyPDF2\n",
" pdf_reader = PyPDF2.PdfReader(pdf_content)\n",
" text = \"\"\n",
" pdf_data = []\n",
" text_type = \"/\".join(blob.name.split(\"/\")[1:-1])\n",
" filename = blob.name.split(\"/\")[-1]\n",
" for page_num in range(len(pdf_reader.pages)):\n",
" page = pdf_reader.pages[page_num]\n",
" text = page.extract_text()\n",
" if text:\n",
" pdf_data.append(\n",
" {\n",
" \"text_type\": text_type,\n",
" \"gcs_path\": \"gs://\"\n",
" + blob.bucket.name\n",
" + \"/\"\n",
" + blob.name,\n",
" \"page_number\": page_num + 1,\n",
" \"text\": text,\n",
" }\n",
" )\n",
" extracted_text.extend(pdf_data)\n",
" # break\n",
" except:\n",
" print(\n",
" f\"Warning: Could not read PDF file '{blob.name}' (might be encrypted or corrupted)\"\n",
" )\n",
" return pd.DataFrame(extracted_text)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "LYkxzkYcZrHE"
},
"outputs": [],
"source": [
"%%time\n",
"extracted_text = get_text_from_pdf(bucket)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "46woC7UPMGLK"
},
"outputs": [],
"source": [
"extracted_text.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "uoD1XE6hM_4J"
},
"outputs": [],
"source": [
"file_count = pd.DataFrame(\n",
" [\n",
" [\n",
" each.split(\"/\")[-1]\n",
" for each in extracted_text[\"gcs_path\"].value_counts().index\n",
" ],\n",
" extracted_text[\"gcs_path\"].value_counts().values,\n",
" ]\n",
").T\n",
"file_count.columns = [\"filename\", \"count\"]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "v_JSQ9M9N84T"
},
"outputs": [],
"source": [
"file_count.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "1m0cdFqnOiI-"
},
"outputs": [],
"source": [
"print(\"Total pages to process...\", file_count[\"count\"].sum())\n",
"print(\"Total files to process...\", file_count.shape[0])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "fy125n33O1Iw"
},
"outputs": [],
"source": [
"print(\"Document name: \", file_count.iloc[0][\"filename\"])\n",
"print(\"Number of pages: \", file_count.iloc[0][\"count\"])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "noYbSyR4O-Mm"
},
"outputs": [],
"source": [
"index = 100\n",
"rich_print(\n",
" \"Name of the Document: ************\\n\",\n",
" extracted_text.iloc[index][\"gcs_path\"].split(\"/\")[-1],\n",
")\n",
"rich_print(\"\\n\\nPage Number: ************\\n\", extracted_text.iloc[index][\"page_number\"])\n",
"rich_print(\"\\n\\nText: ************\\n\", extracted_text.iloc[index][\"text\"])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "5nG6inYdQkne"
},
"source": [
"### Audio Summary Extraction"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "BIT3Ap_xQm3e"
},
"source": [
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"id": "Y3D-w8RDVucY"
},
"outputs": [],
"source": [
"# @title Audio Summary Helper Functions\n",
"\n",
"\n",
"def get_text_from_audio(bucket, model, prompt, time_sleep=5):\n",
" # Iterate over all blobs (files) in the bucket\n",
" audio_metadata = []\n",
" for blob in bucket.list_blobs():\n",
" if blob.name.startswith(PRODUCTION_DATA):\n",
" if blob.name.lower().endswith(\".mp3\"):\n",
" print(\"processing....\", blob.name)\n",
" video_type = \"/\".join(blob.name.split(\"/\")[1:-1])\n",
" gcs_path = \"/\".join(blob.id.split(\"/\")[:-1])\n",
" # print(gcs_path)\n",
" try:\n",
" audio_description = get_gemini_response(\n",
" uri_path=gcs_path,\n",
" model=model,\n",
" mime_type=\"audio/mpeg\",\n",
" prompt=prompt,\n",
" )\n",
" if audio_description:\n",
" audio_metadata.append(\n",
" {\n",
" \"audio_gcs\": \"gs://\"\n",
" + blob.bucket.name\n",
" + \"/\"\n",
" + blob.name,\n",
" \"audio_type\": video_type,\n",
" \"audio_description\": audio_description,\n",
" }\n",
" )\n",
" except:\n",
" print(\"Something Failed........\")\n",
" audio_metadata.append(\n",
" {\n",
" \"audio_gcs\": blob.name,\n",
" \"audio_type\": video_type,\n",
" \"audio_description\": \"\",\n",
" }\n",
" )\n",
" # print(\"sleeping......\")\n",
" time.sleep(time_sleep)\n",
" # break\n",
" return pd.DataFrame(audio_metadata)\n",
"\n",
"\n",
"def get_gcs_uri_list(bucket, data, file_extension):\n",
" gcs_uri_list = []\n",
" for blob in bucket.list_blobs():\n",
" if blob.name.startswith(data):\n",
" if blob.name.lower().endswith(file_extension):\n",
" gcs_path = \"gs://\" + \"/\".join(blob.id.split(\"/\")[:-1])\n",
" gcs_uri_list.append(gcs_path)\n",
" return gcs_uri_list\n",
"\n",
"\n",
"@retry(wait=wait_random_exponential(multiplier=1, max=120), stop=stop_after_attempt(4))\n",
"async def async_generate(prompt, model, gcs_uri, mime_type):\n",
" try:\n",
" safety_settings = {\n",
" HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_ONLY_HIGH,\n",
" HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_ONLY_HIGH,\n",
" HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_ONLY_HIGH,\n",
" HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_ONLY_HIGH,\n",
" }\n",
" # model = GenerativeModel(\n",
" # \"gemini-2.0-flash\",\n",
" # safety_settings = safety_settings\n",
" # )\n",
" # print(\"Hitting\")\n",
"\n",
" response = await model.generate_content_async(\n",
" [prompt, Part.from_uri(gcs_uri, mime_type=mime_type)],\n",
" stream=False,\n",
" )\n",
" # print(len(response.text))\n",
" return response.text\n",
" except Exception as e:\n",
" print(\"Something failed, retrying\")\n",
" print(e)\n",
" with retry.stop_after_attempt(2) as retry_state:\n",
" if retry_state.attempt > 2:\n",
" return None\n",
" raise # Re-raise the exception for tenacity to handle\n",
"\n",
"\n",
"async def batch_and_profile(\n",
" gcs_uris, prompt, model, mime_type, batch_size=2, max_concurrent=4\n",
"):\n",
" start_time = time.time()\n",
" memory_usage = psutil.Process().memory_info().rss / 1024**2\n",
"\n",
" semaphore = asyncio.locks.Semaphore(max_concurrent)\n",
"\n",
" async def process_batch(batch):\n",
" async with semaphore:\n",
" return await asyncio.gather(\n",
" *[async_generate(prompt, model, f, mime_type) for f in batch]\n",
" )\n",
"\n",
" batches = [\n",
" gcs_uris[i : i + batch_size] for i in range(0, len(gcs_uris), batch_size)\n",
" ]\n",
" get_responses = [asyncio.create_task(process_batch(batch)) for batch in batches]\n",
" final_response_list = [\n",
" item for sublist in await asyncio.gather(*get_responses) for item in sublist\n",
" ]\n",
"\n",
" end_time = time.time()\n",
" elapsed_time = end_time - start_time\n",
" final_memory_usage = psutil.Process().memory_info().rss / 1024**2\n",
"\n",
" print(f\"Batch size: {batch_size}\")\n",
" print(f\"Elapsed time: {elapsed_time:.2f} seconds\")\n",
" print(f\"Initial memory usage: {memory_usage:.2f} MB\")\n",
" print(f\"Final memory usage: {final_memory_usage:.2f} MB\")\n",
"\n",
" return final_response_list"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "g5yq02hWQlK6"
},
"outputs": [],
"source": [
"audio_description_extraction_prompt = \"\"\"Transcribe and analyze the audio, identifying key topic shifts or changes in focus. Divide the audio into segments based on these transitions.\n",
"For each segment:\n",
"* **Summarize:** Briefly describe the main topic or theme of the segment.\n",
"* **Contextualize:** Explain how this topic fits into the broader conversation or narrative.\n",
"* **Analyze:** Explore the significance of this topic, the perspectives presented, and any potential biases or underlying assumptions.\n",
"* **Synthesize:** Connect this topic to other themes or ideas mentioned in the audio, highlighting relationships and overarching patterns.\n",
"Conclude with a thematic analysis of the entire audio. Identify the most prominent themes, how they are interconnected, and the overall message or purpose of the audio.\n",
"\"\"\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "rQi4yKwtQr9G"
},
"outputs": [],
"source": [
"%%time\n",
"audio_metadata_flash = get_text_from_audio(\n",
" bucket, gemini_15_flash, audio_description_extraction_prompt, time_sleep=1\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Ragw0q5EZoZy"
},
"outputs": [],
"source": [
"batch_size = 3\n",
"max_concurrent = 4\n",
"\n",
"gcs_uri_list_audio = get_gcs_uri_list(bucket, PRODUCTION_DATA, \".mp3\")\n",
"final_response_list_audio = await batch_and_profile(\n",
" gcs_uri_list_audio,\n",
" audio_description_extraction_prompt,\n",
" gemini_15_pro, # gemini_15_flash #Switch to flash model for much faster processing or if you are getting any error\n",
" \"audio/mpeg\",\n",
" batch_size,\n",
" max_concurrent,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "tRdm_oJ6f4zS"
},
"source": [
"You may see \"Something failed, retrying 429 Resource exhausted....\" warning/error while running the above code. You can ignore them and if the execution failed, you can switch to \"gemini_15_flash\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "XjvgQ4Sgb-Uy"
},
"outputs": [],
"source": [
"audio_metadata_flash = pd.DataFrame([gcs_uri_list_audio, final_response_list_audio]).T\n",
"audio_metadata_flash.columns = [\"audio_gcs\", \"audio_description\"]\n",
"audio_metadata_flash.head(2)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "8fshNBA0RCBx"
},
"outputs": [],
"source": [
"print(\"total files: ....\", len(audio_metadata_flash[\"audio_gcs\"].value_counts().index))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "OPI9sFdrQz9C"
},
"outputs": [],
"source": [
"rich_Markdown(audio_metadata_flash[\"audio_description\"][2])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "sWN6oCYAUru8"
},
"source": [
"### Video Summary Extraction"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "cc4jn361U9on"
},
"source": [
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "58Ga2S6vcRl9"
},
"outputs": [],
"source": [
"batch_size = 5\n",
"max_concurrent = 4\n",
"video_description_extraction_prompt = \"\"\"Transcribe and analyze the video, intelligently segmenting it based on shifts in topic, focus, or narrative progression.\n",
"For each identified segment:\n",
"**Concise Summary**: Distill the core theme or message in 1-2 sentences.\n",
"**Thematic Context**: How does this segment contribute to the overarching narrative or argument?\n",
"**Critical Analysis**: Delve into the segment's implications, perspectives presented, and potential biases.\n",
"**Connections**: Link this segment to other parts of the video, revealing patterns and relationships.\n",
"\n",
"Conclude by synthesizing the video's main themes, their interconnections, and the overarching purpose or message.\n",
"\"\"\"\n",
"gcs_uri_list_video = get_gcs_uri_list(bucket, PRODUCTION_DATA, \".mp4\")\n",
"\n",
"final_response_list_video = await batch_and_profile(\n",
" gcs_uri_list_video,\n",
" video_description_extraction_prompt,\n",
" gemini_15_pro, # gemini_15_flash #Switch to flash model for much faster processing or if you are getting any error\n",
" \"video/mp4\",\n",
" batch_size,\n",
" max_concurrent,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "FQLY14dAflbe"
},
"source": [
"You may see \"Something failed, retrying 429 Resource exhausted....\" warning/error while running the above code. You can ignore them and if the execution failed, you can switch to \"gemini_15_flash\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "5Zy-na9hcb_h"
},
"outputs": [],
"source": [
"video_metadata_flash = pd.DataFrame([gcs_uri_list_video, final_response_list_video]).T\n",
"video_metadata_flash.columns = [\"video_gcs\", \"video_description\"]\n",
"video_metadata_flash.head(2)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "JjjJIqA9Y7Qp"
},
"outputs": [],
"source": [
"print(\"total files: ....\", len(video_metadata_flash[\"video_gcs\"].value_counts().index))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "VL_gMeqyY9LW"
},
"outputs": [],
"source": [
"rich_Markdown(video_metadata_flash[\"video_description\"][3])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ZEMgcMJoacKZ"
},
"source": [
"### Save the intermediate Files"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Le6qMDo3ZtdB"
},
"outputs": [],
"source": [
"# # [Optional]\n",
"# import pickle\n",
"\n",
"# data_to_dump = [extracted_text, audio_metadata_flash, video_metadata_flash]\n",
"\n",
"# gcs_location = \"gs://mlops-for-genai/multimodal-finanace-qa/data/structured/data_extraction_dataframe.pkl\"\n",
"\n",
"# with open(\"data_extraction_dataframe.pkl\", \"wb\") as f:\n",
"# pickle.dump(data_to_dump, f)\n",
"\n",
"\n",
"# # Upload the pickle file to GCS\n",
"# !gsutil cp data_extraction_dataframe.pkl {gcs_location}"
]
}
],
"metadata": {
"colab": {
"name": "2.1_mvp_data_processing.ipynb",
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 0
}