workshops/rag-ops/2.2_mvp_chunk_embeddings.ipynb (1,173 lines of code) (raw):
{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "-PKa6W4wdPWr"
},
"outputs": [],
"source": [
"# Copyright 2024 Google LLC\n",
"#\n",
"# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
"# you may not use this file except in compliance with the License.\n",
"# You may obtain a copy of the License at\n",
"#\n",
"# https://www.apache.org/licenses/LICENSE-2.0\n",
"#\n",
"# Unless required by applicable law or agreed to in writing, software\n",
"# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
"# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
"# See the License for the specific language governing permissions and\n",
"# limitations under the License."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "idM_aIPheQDG"
},
"source": [
"# Stage 2: Building MVP: - 02 Chunk & Embeddings\n",
"\n",
"\n",
"<table align=\"left\">\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://colab.research.google.com/github/GoogleCloudPlatform/generative-ai/blob/main/workshops/rag-ops/2.2_mvp_chunk_embeddings.ipynb\">\n",
" <img src=\"https://cloud.google.com/ml-engine/images/colab-logo-32px.png\" alt=\"Google Colaboratory logo\"><br> Open in Colab\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://console.cloud.google.com/vertex-ai/colab/import/https:%2F%2Fraw.githubusercontent.com%2FGoogleCloudPlatform%2Fgenerative-ai%2Fmain%2Fworkshops%2Frag-ops%2F2.2_mvp_chunk_embeddings.ipynb\">\n",
" <img width=\"32px\" src=\"https://lh3.googleusercontent.com/JmcxdQi-qOpctIvWKgPtrzZdJJK-J3sWE1RsfjZNwshCFgE_9fULcNpuXYTilIR2hjwN\" alt=\"Google Cloud Colab Enterprise logo\"><br> Open in Colab Enterprise\n",
" </a>\n",
" </td> \n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://console.cloud.google.com/vertex-ai/workbench/deploy-notebook?download_url=https://raw.githubusercontent.com/GoogleCloudPlatform/generative-ai/main/workshops/rag-ops/2.2_mvp_chunk_embeddings.ipynb\">\n",
" <img src=\"https://lh3.googleusercontent.com/UiNooY4LUgW_oTvpsNhPpQzsstV5W8F7rYgxgGBD85cWJoLmrOzhVs_ksK_vgx40SHs7jCqkTkCk=e14-rj-sc0xffffff-h130-w32\" alt=\"Vertex AI logo\"><br> Open in Workbench\n",
" </a>\n",
" </td>\n",
" <td style=\"text-align: center\">\n",
" <a href=\"https://github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/rag-ops/2.2_mvp_chunk_embeddings.ipynb\">\n",
" <img src=\"https://cloud.google.com/ml-engine/images/github-logo-32px.png\" alt=\"GitHub logo\"><br> View on GitHub\n",
" </a>\n",
" </td>\n",
"</table>\n",
"\n",
"<div style=\"clear: both;\"></div>\n",
"\n",
"<b>Share to:</b>\n",
"\n",
"<a href=\"https://www.linkedin.com/sharing/share-offsite/?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/rag-ops/2.2_mvp_chunk_embeddings.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/8/81/LinkedIn_icon.svg\" alt=\"LinkedIn logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://bsky.app/intent/compose?text=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/rag-ops/2.2_mvp_chunk_embeddings.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/7/7a/Bluesky_Logo.svg\" alt=\"Bluesky logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://twitter.com/intent/tweet?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/rag-ops/2.2_mvp_chunk_embeddings.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/5/5a/X_icon_2.svg\" alt=\"X logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://reddit.com/submit?url=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/rag-ops/2.2_mvp_chunk_embeddings.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://redditinc.com/hubfs/Reddit%20Inc/Brand/Reddit_Logo.png\" alt=\"Reddit logo\">\n",
"</a>\n",
"\n",
"<a href=\"https://www.facebook.com/sharer/sharer.php?u=https%3A//github.com/GoogleCloudPlatform/generative-ai/blob/main/workshops/rag-ops/2.2_mvp_chunk_embeddings.ipynb\" target=\"_blank\">\n",
" <img width=\"20px\" src=\"https://upload.wikimedia.org/wikipedia/commons/5/51/Facebook_f_logo_%282019%29.svg\" alt=\"Facebook logo\">\n",
"</a> "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "o0oOZgLKfhCi"
},
"source": [
"## Overview\n",
"\n",
"This notebook is the second in a series designed to guide you through building a Minimum Viable Product (MVP) for a Multimodal Retrieval Augmented Generation (RAG) system using the Vertex Gemini API.\n",
"\n",
"Building upon the foundation laid in the first notebook, where we focused on extracting information from diverse data sources like PDFs, audio files, and video, this notebook dives deep into preparing that extracted textual data for efficient retrieval.\n",
"\n",
"**Here's what you'll achieve:**\n",
"\n",
"* **Master Text Chunking:** Learn how to effectively divide extracted text into manageable chunks optimized for embedding generation and subsequent retrieval.\n",
"\n",
"* **Generate Powerful Embeddings:** Understand the importance of embeddings in RAG systems and leverage Vertex AI Embeddings to transform text chunks into meaningful vector representations. We'll utilize the Batch mode feature of Vertex AI Embeddings with BigQuery backing to efficiently process thousands of text chunks in parallel.\n",
"* **Optimize for Scalability:** Gain practical experience with asynchronous processing by using the Async Vertex Gemini API. This allows you to send multiple parallel requests for extracting text from multimodal data (audio and video), significantly speeding up your workflow.\n",
"* **Save and Store:** Implement best practices for saving the intermediate files generated during the chunking and embedding process, ensuring data persistence and efficient retrieval in later stages of your RAG system development.\n",
"\n",
"This notebook provides a crucial bridge between raw data extraction and the core retrieval functionality of your RAG system. By mastering text chunking and embedding generation, you'll be well-equipped to build a robust and scalable MVP.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "6KGP8kNhfklW"
},
"source": [
"## Getting Started"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "HGFDxQ7_flui"
},
"source": [
"### Install Vertex AI SDK for Python\n"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"id": "YcWmeELUeTPq"
},
"outputs": [],
"source": [
"%pip install --upgrade --user --quiet google-cloud-aiplatform"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "SYYzbNlmfvKJ"
},
"source": [
"### Restart runtime\n",
"\n",
"To use the newly installed packages in this Jupyter runtime, you must restart the runtime. You can do this by running the cell below, which restarts the current kernel."
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"id": "icVKaoLAfw6c"
},
"outputs": [],
"source": [
"import sys\n",
"\n",
"if \"google.colab\" in sys.modules:\n",
" import IPython\n",
"\n",
" app = IPython.Application.instance()\n",
" app.kernel.do_shutdown(True)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "oZoekSN8fy2E"
},
"source": [
"<div class=\"alert alert-block alert-warning\">\n",
"<b>⚠️ The kernel is going to restart. Please wait until it is finished before continuing to the next step. ⚠️</b>\n",
"</div>\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "E4rlvfF1f1RA"
},
"source": [
"### Authenticate your notebook environment (Colab only)\n",
"\n",
"If you are running this notebook on Google Colab, run the cell below to authenticate your environment.\n"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"id": "XTaUAqKLf3N8"
},
"outputs": [],
"source": [
"import sys\n",
"\n",
"if \"google.colab\" in sys.modules:\n",
" from google.colab import auth\n",
"\n",
" auth.authenticate_user()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "iQJQgZKXf6Mx"
},
"source": [
"### Set Google Cloud project information, GCS Bucket and initialize Vertex AI SDK\n",
"\n",
"To get started using Vertex AI, you must have an existing Google Cloud project and [enable the Vertex AI API](https://console.cloud.google.com/flows/enableapi?apiid=aiplatform.googleapis.com).\n",
"\n",
"Learn more about [setting up a project and a development environment](https://cloud.google.com/vertex-ai/docs/start/cloud-environment)."
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"id": "FqXU2Ptvf5LA"
},
"outputs": [],
"source": [
"import os\n",
"import sys\n",
"\n",
"from google.cloud import storage\n",
"import vertexai\n",
"\n",
"PROJECT_ID = \"[your-project-id]\" # @param {type:\"string\"}\n",
"LOCATION = \"us-central1\"\n",
"BUCKET_NAME = \"mlops-for-genai\"\n",
"\n",
"if PROJECT_ID == \"[your-project-id]\":\n",
" PROJECT_ID = str(os.environ.get(\"GOOGLE_CLOUD_PROJECT\"))\n",
"\n",
"if not PROJECT_ID or PROJECT_ID == \"[your-project-id]\" or PROJECT_ID == \"None\":\n",
" raise ValueError(\"Please set your PROJECT_ID\")\n",
"\n",
"\n",
"vertexai.init(project=PROJECT_ID, location=LOCATION)\n",
"\n",
"# Initialize cloud storage\n",
"storage_client = storage.Client(project=PROJECT_ID)\n",
"bucket = storage_client.bucket(BUCKET_NAME)"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"id": "6AbGiKORhxQ7"
},
"outputs": [],
"source": [
"# # Variables for data location. Do not change.\n",
"\n",
"PRODUCTION_DATA = \"multimodal-finanace-qa/data/unstructured/production/\"\n",
"PICKLE_FILE_NAME = \"data_extraction_dataframe.pkl\"\n",
"EMBEDDING_INPUT_PATH = \"multimodal-finanace-qa/data/embeddings\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "s9-h_WOcgAKX"
},
"source": [
"### Import libraries\n"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
"id": "OaW7NsbHgAoo"
},
"outputs": [],
"source": [
"# Library\n",
"\n",
"import pickle\n",
"\n",
"from google.cloud import storage\n",
"import pandas as pd\n",
"from rich.markdown import Markdown as rich_Markdown\n",
"from vertexai.generative_models import (\n",
" GenerativeModel,\n",
" HarmBlockThreshold,\n",
" HarmCategory,\n",
" Part,\n",
")\n",
"from vertexai.language_models import TextEmbeddingInput, TextEmbeddingModel"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "A9hij3nhgDz8"
},
"source": [
"### Load the Gemini 2.0 models\n",
"\n",
"To learn more about all [Gemini API models on Vertex AI](https://cloud.google.com/vertex-ai/generative-ai/docs/learn/models#gemini-models).\n",
"\n",
"The Gemini model family has several model versions. You will start by using Gemini 2.0. Gemini 2.0 is a more lightweight, fast, and cost-efficient model. This makes it a great option for prototyping.\n"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {
"id": "7xvFkagTgHMc"
},
"outputs": [],
"source": [
"MODEL_ID_FLASH = \"gemini-2.0-flash\" # @param {type:\"string\"}\n",
"MODEL_ID_PRO = \"gemini-2.0-flash\" # @param {type:\"string\"}\n",
"\n",
"\n",
"gemini_15_flash = GenerativeModel(MODEL_ID_FLASH)\n",
"gemini_15_pro = GenerativeModel(MODEL_ID_PRO)"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"cellView": "form",
"id": "oS1ar31xYmkR"
},
"outputs": [],
"source": [
"# @title Gemini API Call Functions\n",
"\n",
"\n",
"def get_gemini_response(\n",
" model,\n",
" generation_config=None,\n",
" safety_settings=None,\n",
" uri_path=None,\n",
" mime_type=None,\n",
" prompt=None,\n",
"):\n",
" if not generation_config:\n",
" generation_config = {\n",
" \"max_output_tokens\": 8192,\n",
" \"temperature\": 1,\n",
" \"top_p\": 0.95,\n",
" }\n",
"\n",
" if not safety_settings:\n",
" safety_settings = {\n",
" HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_ONLY_HIGH,\n",
" HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_ONLY_HIGH,\n",
" HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_ONLY_HIGH,\n",
" HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_ONLY_HIGH,\n",
" }\n",
"\n",
" uri = \"gs://\" + uri_path\n",
" file = Part.from_uri(mime_type=mime_type, uri=uri)\n",
" responses = model.generate_content(\n",
" [file, prompt],\n",
" generation_config=generation_config,\n",
" safety_settings=safety_settings,\n",
" stream=True,\n",
" )\n",
" final_response = []\n",
" for response in responses:\n",
" try:\n",
" final_response.append(response.text)\n",
" except ValueError:\n",
" # print(\"Something is blocked...\")\n",
" final_response.append(\"blocked\")\n",
"\n",
" return \"\".join(final_response)\n",
"\n",
"\n",
"def get_load_dataframes_from_gcs():\n",
" gcs_path = \"multimodal-finanace-qa/data/structured/\" + PICKLE_FILE_NAME\n",
" # print(\"GCS PAth: \", gcs_path)\n",
" blob = bucket.blob(gcs_path)\n",
"\n",
" # Download the pickle file from GCS\n",
" blob.download_to_filename(f\"{PICKLE_FILE_NAME}\")\n",
"\n",
" # Load the pickle file into a list of dataframes\n",
" with open(f\"{PICKLE_FILE_NAME}\", \"rb\") as f:\n",
" dataframes = pickle.load(f)\n",
"\n",
" # Assign the dataframes to variables\n",
" extracted_text, audio_metadata_flash, video_metadata_flash = dataframes\n",
"\n",
" return extracted_text, audio_metadata_flash, video_metadata_flash"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "KKT4gg2ybwaR"
},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "20h6TWe0w8YY"
},
"source": [
"## Step 2.1: Data Chunking"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Spw0nwSUb_et"
},
"source": [
"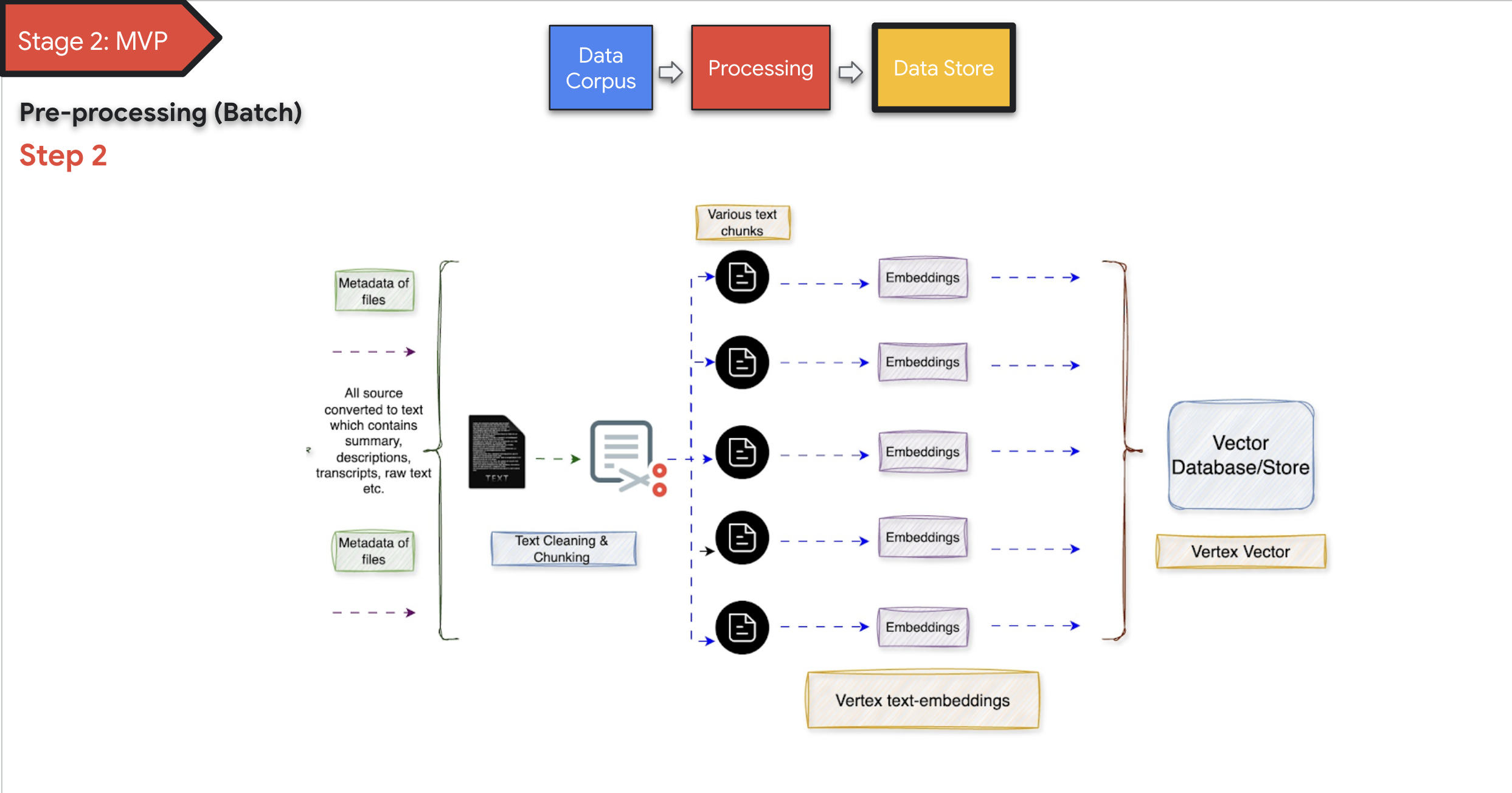"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {
"id": "Jk5387FCjlAv"
},
"outputs": [],
"source": [
"# Get the data that has been extracted in the previous step: Data Processing.\n",
"# Make sure that you have ran the previous notebook: stage_2_mvp_data_processing.ipynb\n",
"extracted_text, audio_metadata_flash, video_metadata_flash = (\n",
" get_load_dataframes_from_gcs()\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "gDEsvCMls1i1"
},
"source": [
"<img src=\"https://storage.googleapis.com/gemini-lavi-asset/img/Step2-Chunking.png\" width=\"500\" />"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {
"cellView": "form",
"id": "XcnsZI7IuGhS"
},
"outputs": [],
"source": [
"# @title Text Chunking Helper Functions\n",
"\n",
"\n",
"def split_text_into_chunks(df, text_column, chunk_size):\n",
" \"\"\"Splits text into chunks of specified size, preserving other column values.\"\"\"\n",
"\n",
" # Create a list of new dataframes, one for each chunk\n",
" new_dfs = []\n",
" for _, row in df.iterrows():\n",
" text_chunks = [\n",
" row[text_column][i : i + chunk_size]\n",
" for i in range(0, len(row[text_column]), chunk_size)\n",
" ]\n",
" for chunk in text_chunks:\n",
" new_row = row.copy() # Copy all other columns\n",
" new_row[text_column] = chunk\n",
" new_dfs.append(pd.DataFrame([new_row]))\n",
"\n",
" return pd.concat(new_dfs, ignore_index=True) # Combine into single dataframe"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {
"id": "T9V-rk2Ds134"
},
"outputs": [],
"source": [
"chunk_size = 500\n",
"extracted_text_chunk_df = split_text_into_chunks(extracted_text, \"text\", chunk_size)\n",
"video_metadata_chunk_df = split_text_into_chunks(\n",
" video_metadata_flash, \"video_description\", chunk_size\n",
")\n",
"audio_metadata_chunk_df = split_text_into_chunks(\n",
" audio_metadata_flash, \"audio_description\", chunk_size\n",
")"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"id": "WGeqOVsYuP_G"
},
"outputs": [],
"source": [
"extracted_text_chunk_df.head()"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {
"id": "qpqRxAjcgwD-"
},
"outputs": [],
"source": [
"audio_metadata_chunk_df.head(2)"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {
"id": "vSNtctGXgyOt"
},
"outputs": [],
"source": [
"video_metadata_chunk_df.head(2)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "SmKV4D5GvKEN"
},
"source": [
"Original Page Text"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "8RJS82SmuTSE"
},
"outputs": [],
"source": [
"rich_Markdown(\n",
" extracted_text[\n",
" (extracted_text[\"page_number\"] == 3)\n",
" & (\n",
" extracted_text[\"gcs_path\"]\n",
" == \"gs://mlops-for-genai/multimodal-finanace-qa/data/unstructured/production/blogpost/Gemma on Google Kubernetes Engine deep dive _ Google Cloud Blog.pdf\"\n",
" )\n",
" ][\"text\"].values[0]\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "zHNQfpFNvL_f"
},
"source": [
"Chunked Page text - Split into three chunks based on 500 characters."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "4cmPjaN-u12e"
},
"outputs": [],
"source": [
"rich_Markdown(extracted_text_chunk_df.iloc[6][\"text\"])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "K_Q4neAXvDec"
},
"outputs": [],
"source": [
"rich_Markdown(extracted_text_chunk_df.iloc[7][\"text\"])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "C_yLksClvFUP"
},
"outputs": [],
"source": [
"rich_Markdown(extracted_text_chunk_df.iloc[8][\"text\"])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "XLLFCkPlvfXa"
},
"source": [
"## Step 2.2: Creating Embeddings"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {
"cellView": "form",
"id": "rbIrfwc3vgKD"
},
"outputs": [],
"source": [
"# @title Embedding Helper Functions\n",
"\n",
"\n",
"def get_text_embeddings(\n",
" texts: list[str] = [\"banana muffins? \", \"banana bread? banana muffins?\"],\n",
" task: str = \"RETRIEVAL_DOCUMENT\",\n",
" model_name: str = \"text-embedding-005\",\n",
") -> list[list[float]]:\n",
" # print(\"doing...\")\n",
" \"\"\"Embeds texts with a pre-trained, foundational model.\"\"\"\n",
" model = TextEmbeddingModel.from_pretrained(model_name)\n",
" inputs = [TextEmbeddingInput(text, task) for text in texts]\n",
" embeddings = model.get_embeddings(inputs)\n",
" return [embedding.values for embedding in embeddings][0]\n",
"\n",
"\n",
"def backup_metadata_in_pickle(\n",
" extracted_text, video_metadata, audio_metadata, index_db, output_path_with_name\n",
"):\n",
" import pickle\n",
"\n",
" data_to_save = {\n",
" \"extracted_text\": extracted_text,\n",
" \"video_metadata\": video_metadata,\n",
" \"audio_metadata\": audio_metadata,\n",
" \"index_db\": index_db,\n",
" }\n",
" print(\"Backing up the metadata in: \", output_path_with_name + \".pkl\")\n",
" with open(f\"{output_path_with_name}.pkl\", \"wb\") as f:\n",
" pickle.dump(data_to_save, f)\n",
"\n",
"\n",
"import uuid\n",
"\n",
"uuid.uuid4()\n",
"\n",
"\n",
"def assign_unique_uuids(dataframes):\n",
" \"\"\"Assigns unique UUIDs to each row of multiple dataframes.\n",
"\n",
" Args:\n",
" dataframes (list): A list of pandas DataFrames.\n",
"\n",
" Returns:\n",
" list: A list of DataFrames with the 'uid' column added.\n",
" \"\"\"\n",
"\n",
" result_dataframes = []\n",
" for df in dataframes:\n",
" df[\"uid\"] = df.apply(lambda row: str(uuid.uuid4().hex), axis=1)\n",
" result_dataframes.append(df)\n",
"\n",
" return result_dataframes\n",
"\n",
"\n",
"import json\n",
"\n",
"\n",
"def create_jsonl_file(\n",
" extracted_text_chunk_df,\n",
" video_metadata_chunk_df,\n",
" audio_metadata_chunk_df,\n",
" bucket_object,\n",
" jsonl_file_path,\n",
"):\n",
" \"\"\"\n",
" Creates a JSONL file containing the combined text, video_description, and audio_description from the given dataframes.\n",
"\n",
" Args:\n",
" extracted_text_chunk_df (pandas.DataFrame): The dataframe containing extracted text chunks.\n",
" video_metadata_chunk_df (pandas.DataFrame): The dataframe containing video metadata.\n",
" audio_metadata_chunk_df (pandas.DataFrame): The dataframe containing audio metadata.\n",
" \"\"\"\n",
"\n",
" json_data = []\n",
" df_data = []\n",
"\n",
" for index, row in extracted_text_chunk_df.iterrows():\n",
" json_data.append({\"content\": row[\"text\"]})\n",
"\n",
" df_data.append([row[\"uid\"], \"text\", row[\"text\"]])\n",
"\n",
" for index, row in video_metadata_chunk_df.iterrows():\n",
" json_data.append({\"content\": row[\"video_description\"]})\n",
"\n",
" df_data.append([row[\"uid\"], \"video_description\", row[\"video_description\"]])\n",
"\n",
" for index, row in audio_metadata_chunk_df.iterrows():\n",
" json_data.append({\"content\": row[\"audio_description\"]})\n",
"\n",
" df_data.append([row[\"uid\"], \"audio_description\", row[\"audio_description\"]])\n",
"\n",
" # Convert the JSON data to a string\n",
" jsonl_data = \"\"\n",
" for item in json_data:\n",
" jsonl_data += json.dumps(item) + \"\\n\"\n",
"\n",
" # # Upload the JSONL data to GCS\n",
" # blob = bucket.blob(jsonl_file_path+\"/combined_data.jsonl\")\n",
" # blob.upload_from_string(jsonl_data)\n",
" # print(f\"File uploaded to GCS: {blob.public_url}\")\n",
"\n",
" # gcs_path_jsonl_data = f\"gs://{bucket.name}/{blob.name}\"\n",
"\n",
" # return pd.DataFrame(json_data), pd.DataFrame(df_data, columns=['uid','type', 'content']), gcs_path_jsonl_data\n",
" return pd.DataFrame(json_data), pd.DataFrame(\n",
" df_data, columns=[\"uid\", \"type\", \"content\"]\n",
" )\n",
"\n",
"\n",
"def load_jsonl_from_gcs(bucket, file_path):\n",
" \"\"\"Loads a JSONL file from a GCS bucket and converts it into a DataFrame.\n",
"\n",
" Args:\n",
" bucket_name (str): The name of the GCS bucket.\n",
" file_path (str): The path to the JSONL file within the bucket.\n",
"\n",
" Returns:\n",
" pandas.DataFrame: The DataFrame created from the JSONL data.\n",
" \"\"\"\n",
"\n",
" # storage_client = storage.Client()\n",
" # bucket = storage_client.bucket(bucket_name)\n",
" file_path_final = \"/\".join(file_path.split(\"//\")[1].split(\"/\")[1:])\n",
" print(file_path_final)\n",
" blob = bucket.blob(file_path_final)\n",
"\n",
" with blob.open(\"rb\") as f:\n",
" data = []\n",
" for line in f:\n",
" instance = json.loads(line)\n",
" content = instance[\"instance\"][\"content\"]\n",
" predictions = instance[\"predictions\"][0][\"embeddings\"][\"values\"]\n",
" data.append({\"content\": content, \"predictions\": predictions})\n",
"\n",
" df = pd.DataFrame(data)\n",
" return df"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {
"id": "804EicChwNEL"
},
"outputs": [],
"source": [
"(extracted_text_chunk_df, video_metadata_chunk_df, audio_metadata_chunk_df) = (\n",
" assign_unique_uuids(\n",
" [extracted_text_chunk_df, video_metadata_chunk_df, audio_metadata_chunk_df],\n",
" )\n",
")"
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {
"id": "LSIOvM-X2LhI"
},
"outputs": [],
"source": [
"extracted_text_chunk_df.head(2)"
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {
"id": "kfxNC__5g4Lc"
},
"outputs": [],
"source": [
"video_metadata_chunk_df.head(2)"
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {
"id": "yUUNSmno10Ma"
},
"outputs": [],
"source": [
"json_db_emb, index_db = create_jsonl_file(\n",
" extracted_text_chunk_df,\n",
" video_metadata_chunk_df,\n",
" audio_metadata_chunk_df,\n",
" bucket,\n",
" EMBEDDING_INPUT_PATH,\n",
")"
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {
"id": "VVELNMes2Icq"
},
"outputs": [],
"source": [
"index_db.head()"
]
},
{
"cell_type": "code",
"execution_count": 22,
"metadata": {
"id": "PcAwdS9f1YHK"
},
"outputs": [],
"source": [
"index_db.shape"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "jRDs4y89sA2V"
},
"source": [
"You can skip this part and load the already processed embeddings."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "W0jArGyx2PzH"
},
"outputs": [],
"source": [
"# gcs_path_jsonl_data"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "sFAwYi8NE188"
},
"source": [
"This code snippet grants necessary permissions to a service account to interact with Google Cloud Storage and Vertex AI. This is often a required step when setting up integrations between different Google Cloud services, such as using a Vertex AI model within BigQuery."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "GgSZygeI6wSI"
},
"outputs": [],
"source": [
"# # # Refer here: https://cloud.google.com/bigquery/docs/generate-text-tutorial#grant-permissions\n",
"\n",
"# # Grant the Storage Object Creator role to the service account associated with\n",
"# # the AI Platform service agent. This allows the service agent to write objects\n",
"# # to the specified Cloud Storage bucket.\n",
"\n",
"# !gsutil iam ch \\\n",
"# \"$(gcloud projects get-iam-policy $PROJECT_ID \\\n",
"# --flatten=\"bindings[].members\" \\\n",
"# --filter=\"bindings.role:roles/aiplatform.serviceAgent\" \\\n",
"# --format=\"value(bindings.members)\"):roles/storage.objectCreator\" \\\n",
"# gs://mlops-for-genai\n",
"\n",
"# # # If you have multiple service accounts and getting an error: CommandException: Incorrect member type for binding serviceAccount:, use this:\n",
"# # !SERVICE_ACCOUNTS=$(gcloud projects get-iam-policy $PROJECT_ID \\\n",
"# # --flatten=\"bindings[].members\" \\\n",
"# # --filter=\"bindings.role:roles/aiplatform.serviceAgent\" \\\n",
"# # --format=\"value(bindings.members)\")\n",
"# # !for SERVICE_ACCOUNT in $SERVICE_ACCOUNTS; do gsutil iam ch \"$SERVICE_ACCOUNT:roles/storage.objectCreator\" gs://mlops-for-genai; done"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "TfZT2thHv9N9"
},
"outputs": [],
"source": [
"# # # Generate Embeddings. It will take roughly 2-4 minutes\n",
"\n",
"# from vertexai.language_models import TextEmbeddingInput, TextEmbeddingModel\n",
"# from vertexai.preview import language_models\n",
"\n",
"# input_uri = (\n",
"# gcs_path_jsonl_data\n",
"# )\n",
"# output_uri = \"gs://mlops-for-genai/multimodal-finanace-qa/data/embeddings/combined_data_output/\"\n",
"\n",
"# textembedding_model = language_models.TextEmbeddingModel.from_pretrained(\n",
"# \"text-embedding-005\"\n",
"# )\n",
"\n",
"# batch_prediction_job = textembedding_model.batch_predict(\n",
"# dataset=[input_uri],\n",
"# destination_uri_prefix=output_uri,\n",
"# )"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "dEWoFY_aSVko"
},
"source": [
"You know your job is successful, if you see \"JobState.JOB_STATE_SUCCEEDED\" in the second last line. If you don't see that and get error, refer below."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "zNmLF_gPIDAZ"
},
"source": [
"if you receive the following error:\n",
"\n",
"` \"message: \"Failed to run inference job. Query error: bqcx-xxxxxxxxxx-xxxx@gcp-sa-bigquery-condel.iam.gserviceaccount.com does not have the permission to access or use the endpoint. Please grant the Vertex AI user role to the service account following https://cloud.google.com/bigquery/docs/generate-text-tutorial#grant-permissions. If issue persists, contact bqml-feedback@google.com for help. at [4:1]\"\"`\n",
"\n",
"Copy the `\"bqcx-xxxxxxxxxx-xxxx@gcp-sa-bigquery-condel.iam.gserviceaccount.com\"` as is and run the following IAM permission command below. Example:\n",
"\n",
"!gcloud projects add-iam-policy-binding $PROJECT_ID \\\n",
" --member=\"serviceAccount:bqcx-xxxxxxxxxx-xxxx@gcp-sa-bigquery-condel.iam.gserviceaccount.com\" \\\n",
" --role=\"roles/aiplatform.user\""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "MRbBwiXHRm-j"
},
"source": [
"Make sure you get \"version: 1\" as the last line of the output. Then re-run the \"# # Generate Embeddings \" block, a cell above this one, before procedding further."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "yfKKEuGZRVaJ"
},
"outputs": [],
"source": [
"# # Grant the AI Platform User role to a specific service account. This allows the\n",
"# # service account to use AI Platform resources, such as models.\n",
"\n",
"# !gcloud projects add-iam-policy-binding $PROJECT_ID \\\n",
"# --member=\"serviceAccount:<replace with BQ service-account shown in error>\" \\\n",
"# --role=\"roles/aiplatform.user\""
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {
"id": "OE0LPe5oD3kU"
},
"outputs": [],
"source": [
"# print(batch_prediction_job.display_name)\n",
"# print(batch_prediction_job.resource_name)\n",
"# print(batch_prediction_job.state)"
]
},
{
"cell_type": "code",
"execution_count": 24,
"metadata": {
"id": "NgT1baPND5Ii"
},
"outputs": [],
"source": [
"# # Access the output information\n",
"# output_info = batch_prediction_job.output_info\n",
"\n",
"# # The output_info is a list of dictionaries, each with a 'gcs_output_directory' key\n",
"# # In your case, you're expecting a single output file, so you can access it like this:\n",
"# output_dir = output_info.gcs_output_directory\n",
"\n",
"# # Construct the full path to the JSONL file\n",
"# jsonl_file_path = f\"{output_dir}/000000000000.jsonl\"\n",
"\n",
"# print(jsonl_file_path)"
]
},
{
"cell_type": "code",
"execution_count": 25,
"metadata": {
"id": "AmcvI-tBu1Wz"
},
"outputs": [],
"source": [
"# If you want to run your own version of embeddings using Batch Vertex AI Embeddings, then you can run previous cells.\n",
"\n",
"jsonl_file_path = \"gs://mlops-for-genai/multimodal-finanace-qa/data/embeddings/combined_data_output/prediction-model-2024-10-29T19:19:00.826060Z/000000000000.jsonl\""
]
},
{
"cell_type": "code",
"execution_count": 26,
"metadata": {
"id": "Q0slqNy6v4hs"
},
"outputs": [],
"source": [
"%%time\n",
"embedding_df = load_jsonl_from_gcs(bucket, jsonl_file_path)"
]
},
{
"cell_type": "code",
"execution_count": 27,
"metadata": {
"id": "i1J22R9g3fmi"
},
"outputs": [],
"source": [
"embedding_df.tail()"
]
},
{
"cell_type": "code",
"execution_count": 28,
"metadata": {
"id": "cEUw5ttj3hXV"
},
"outputs": [],
"source": [
"print(\"Size of embedding_df: \", embedding_df.shape)\n",
"print(\"Size of index_db: \", index_db.shape)"
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {
"id": "oFOlKTyq3j7X"
},
"outputs": [],
"source": [
"# Joining embedding_df with the index_df\n",
"index_db_final = index_db.merge(embedding_df, on=\"content\", how=\"left\")"
]
},
{
"cell_type": "code",
"execution_count": 30,
"metadata": {
"id": "YA17Sy-r3lWO"
},
"outputs": [],
"source": [
"index_db_final.head()"
]
},
{
"cell_type": "code",
"execution_count": 31,
"metadata": {
"id": "hNyD4jWK3nsX"
},
"outputs": [],
"source": [
"# to test if mapping is done right.\n",
"test_index = 5000\n",
"print(\n",
" \"*****original emb in embedding_db: *****\\n\",\n",
" embedding_df.iloc[test_index][\"predictions\"][:5],\n",
")\n",
"print(\n",
" \"\\n*****emb in index_db****\\n\",\n",
" index_db_final[\n",
" index_db_final[\"content\"] == embedding_df.iloc[test_index][\"content\"]\n",
" ][\"predictions\"].values[0][:5],\n",
")\n",
"print(\n",
" \"\\n*****Original content in embedding_db *****\",\n",
" embedding_df.iloc[test_index][\"content\"],\n",
")\n",
"print(\n",
" \"\\n*****content in index_db*****\",\n",
" index_db_final[\n",
" index_db_final[\"content\"] == embedding_df.iloc[test_index][\"content\"]\n",
" ][\"content\"].values[0],\n",
")"
]
},
{
"cell_type": "code",
"execution_count": 32,
"metadata": {
"id": "tjybxr1q3p0V"
},
"outputs": [],
"source": [
"index_db_final.value_counts(\"type\")"
]
},
{
"cell_type": "code",
"execution_count": 33,
"metadata": {
"id": "5oIf2UVOxilV"
},
"outputs": [],
"source": [
"index_db_final.columns = [\"uid\", \"type\", \"content\", \"embeddings\"]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "jOxi5i0q7edS"
},
"source": [
"### Save the intermediate Files"
]
},
{
"cell_type": "code",
"execution_count": 34,
"metadata": {
"id": "XzjLU7rt7eFu"
},
"outputs": [],
"source": [
"# # [Optional]\n",
"\n",
"# import pickle\n",
"\n",
"# pickle_file_name =\"index_db.pkl\"\n",
"# data_to_dump = [index_db_final, extracted_text_chunk_df,video_metadata_chunk_df,audio_metadata_chunk_df]\n",
"\n",
"# gcs_location = f\"gs://mlops-for-genai/multimodal-finanace-qa/data/embeddings/{pickle_file_name}\"\n",
"\n",
"# with open(f\"{pickle_file_name}\", \"wb\") as f:\n",
"# pickle.dump(data_to_dump, f)\n",
"\n",
"\n",
"# # Upload the pickle file to GCS\n",
"# !gsutil cp {pickle_file_name} {gcs_location}"
]
}
],
"metadata": {
"colab": {
"name": "2.2_mvp_chunk_embeddings.ipynb",
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 0
}