train_rick/02_grpo.ipynb (488 lines of code) (raw):
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 🧠 Mastering LLM Fine-Tuning with TRL – Group Relative Policy Optimization\n",
"\n",
"Welcome! This notebook is part of a tutorial series where you'll learn how to fine-tune Large Language Models (LLMs) using 🤗 TRL.\n",
"We introduce key concepts, set up the required tools, and use techniques like Supervised Fine-Tuning (SFT) and Group-Relative Policy Optimization (GRPO).\n",
"\n",
"## 📋 Prerequisites\n",
"\n",
"Before you begin, make sure you have the following:\n",
"\n",
"* A working knowledge of Python and PyTorch\n",
"* A basic understanding of machine learning and deep learning concepts\n",
"* Access to a GPU accelerator – this notebook is designed to run with **at least 16GB of GPU memory**, such as what is available for free on [Google Colab](https://colab.research.google.com). Runtime Tab -> Change runtime type -> T4 (GPU).\n",
"* The `trl` library installed – this tutorial has been tested with **TRL version 0.17**\n",
" If you don’t have `trl` installed yet, you can install it by running the following code block:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%pip install trl"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* A [Hugging Face account](https://huggingface.co) with a configured access token. If needed, run the following code.\n",
"This will prompt you to enter your Hugging Face access token. You can generate one from your Hugging Face account settings under [Access Tokens](https://huggingface.co/settings/tokens). The token must have `Write access to contents/settings of all repos under your personal namespace`"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from huggingface_hub import notebook_login\n",
"\n",
"notebook_login()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 🔄 Quick Recap of the Last Session\n",
"\n",
"In the previous session, we explored Supervised fine-tuning (SFT) and how to use it to post-train a language model on a custom dataset.\n",
"\n",
"* SFT is a technique used to adapt a pre-trained (base) language model to a specific task or domain by training it on a labeled dataset.\n",
"* We used the `trl` library to load a pre-trained model, and then fine-tuned it on a custom dataset.\n",
"* We also discussed the importance of data preprocessing and how to prepare your dataset for training.\n",
"* We discussed how to manage memory, which is crucial when working with large models.\n",
"* We pushed the fine-tuned model to the Hugging Face Hub, making it accessible for others to use.\n",
"* We showed that, even if the model is now capable of be conversational, it is still not very good at scientific tasks."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import transformers\n",
"import textwrap\n",
"\n",
"pipeline = transformers.pipeline(task=\"text-generation\", model=\"qgallouedec/SmolLM2-360M-Rickified\")\n",
"\n",
"question = \"During a race, a runner maintains a constant velocity of 8 meters per second for 15 seconds. What is the total displacement of the runner?\"\n",
"prompt = [{\"role\": \"user\", \"content\": question}]\n",
"\n",
"generated_text = pipeline(prompt, max_new_tokens=512)[0][\"generated_text\"] # [{'role': 'user', 'content': \"How do ...\"}, {'role': 'assistant', 'content': \"<think>Alright, ...\"}]\n",
"completion = generated_text[1:] # [{'role': 'assistant', 'content': \"<think>Alright, ...\"}]\n",
"print(textwrap.fill(completion[0][\"content\"], width=120))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 🤮 Fun finding\n",
"\n",
"It seems that Rick can burp continuously when asked certain questions!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"question = \"A 3 kg block of copper decreases in temperature from 150°C to 50°C. If copper's specific heat capacity is 0.39 J/g°C, calculate the energy released by the block.\"\n",
"prompt = [{\"role\": \"user\", \"content\": question}]\n",
"\n",
"generated_text = pipeline(prompt, max_new_tokens=512)[0][\"generated_text\"] # [{'role': 'user', 'content': \"How do ...\"}, {'role': 'assistant', 'content': \"<think>Alright, ...\"}]\n",
"completion = generated_text[1:] # [{'role': 'assistant', 'content': \"<think>Alright, ...\"}]\n",
"print(textwrap.fill(completion[0][\"content\"], width=120))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Our goal here is to continue fine-tuning our model to improve its performance on scientific tasks. To do this, we’ll use a technique that has recently proven highly effective and led to the development of some of the best-performing reasoning models, such as DeepSeek-R1 and Qwen3: RLVR — **Reinforcement Learning with Verifiable Rewards**.\n",
"\n",
"## ✅ What is RLVR?\n",
"\n",
"The RLVR approach deals with problems where it is possible to check whether an answer is correct or not. Or, more generally, where it's possible to objectively assign a score to an answer.\n",
"\n",
"In our case, we want our model (Rick) to first lay out its reasoning, enclosed in `<think></think>` tags, and then provide the final answer after.\n",
"\n",
"These two requirements can be implemented as functions."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# During a race, a runner maintains a constant velocity of 8 meters per second for 15 seconds. What is the total displacement of the runner?\n",
"\n",
"# Correct answer, correct format\n",
"completion_1 = [\n",
" {\n",
" \"role\": \"assistant\",\n",
" \"content\": \"<think>Alright, let's break this down. The total displacement of the runner can be calculated using the formula: displacement = velocity * time. In this case, the velocity is 8 m/s and the time is 15 seconds. So, the total displacement is 8 m/s * 15 s = 120 meters.</think> The total displacement of the runner is 120 meters.\"\n",
" }\n",
"]\n",
"# Wrong format, correct answer\n",
"completion_2 = [\n",
" {\n",
" \"role\": \"assistant\",\n",
" \"content\": \"The total displacement of the runner is 120 meters. To calculate this, we use the formula: displacement = velocity * time. In this case, the velocity is 8 m/s and the time is 15 seconds. So, the total displacement is 8 m/s * 15 s = 120 meters.\"\n",
" }\n",
"]\n",
"# Wrong answer, correct format\n",
"completion_3 = [\n",
" {\n",
" \"role\": \"assistant\",\n",
" \"content\": \"<think>Okay, let's analyze the problem. The formula for displacement is: displacement = velocity * time. Here, the velocity is 8 m/s and the time is 15 seconds. So, the total displacement would be 8 m/s * 15 s = 80 meters.</think> The total displacement of the runner is 80 meters.\"\n",
" }\n",
"]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's check the format first:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import re\n",
"\n",
"def format_reward(completions, **kwargs):\n",
" pattern = r\"^<think>(?!.*<think>)(.*?)</think>.*$\"\n",
" completion_contents = [completion[0][\"content\"] for completion in completions]\n",
" matches = [re.match(pattern, content, re.DOTALL | re.MULTILINE) for content in completion_contents]\n",
" return [1.0 if match else 0.0 for match in matches]\n",
"\n",
"format_reward([completion_1, completion_2, completion_3])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let's check the correctness of the answer. We can do this by checking if the answer is in the list of possible answers. If it is, we can return a reward of 1.0, otherwise we return 0.0. It's pretty basic, not very robust, but it works for our basic use case. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def correctness_reward(completions, solution, **kwargs):\n",
" rewards = []\n",
" for completion, ground_truth in zip(completions, solution):\n",
" content = completion[0][\"content\"]\n",
" reward = 1.0 if ground_truth in content else 0.0\n",
" rewards.append(reward)\n",
" return rewards\n",
"\n",
"correctness_reward([completion_1, completion_2, completion_3], solution=[\"120 meters\", \"120 meters\", \"120 meters\"])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The function above provides a working example, but as you can see, it's not very robust. For instance, if the model returns `\"120 m\"` instead of `\"120 meters\"`, the function will output `0.0`, even though the answer is actually correct.\n",
"\n",
"Parsing a model’s response may seem like a minor detail, but it's actually very important. There are advanced methods to handle this, but today we'll keep it simple. We'll just make our reward function a bit more robust by comparing the model’s output not to a single correct answer, but to a list of acceptable answers.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def correctness_reward(completions, solutions, **kwargs):\n",
" rewards = []\n",
" for completion, ground_truths in zip(completions, solutions):\n",
" content = completion[0][\"content\"]\n",
" matches = [ground_truth in content for ground_truth in ground_truths]\n",
" reward = 1.0 if any(matches) else 0.0\n",
" rewards.append(reward)\n",
" return rewards"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And we will be using it like this:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"correctness_reward([completion_1], solutions=[[ \"120 m\", \"120.0 m\", \"120 meters\", \"120m\", \"120.0 meters\"]])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Once again, the above rewards are determinisitc, it means that there is not need for a reward model here. You may be familiar with the RLHF (Reinforcement Learning from Human Feedback) approach, where a reward model is trained to predict the reward for a given input. **This is not the case here.** That's why we call this approach **Verifiable Rewards**.\n",
"\n",
"## 👨👨👦👦 Group Relative Policy Optimization (GRPO)\n",
"\n",
"Now the goal is to train a model that maximize both rewards. To do this, we will be using Group Relative Policy Optimization (GRPO), a technique that has been shown to be effective in training models with verifiable rewards.\n",
"\n",
"The following diagram illustrates how GRPO works:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can break the process down into several steps. The goal here isn’t to dive deep into the math or underlying theory, but rather to build a minimal understanding of how the method works in practice.\n",
"\n",
"#### 1. Sample a batch of prompts\n",
"\n",
"```python\n",
"prompts = [\"The capital of Canada is\", \"The sky is\"]\n",
"```\n",
"\n",
"#### 2. For each prompt, generate a list of completions\n",
"\n",
"```python\n",
"completions = [[\"Ottawa\", \"Toronto\", \"Edmonton\"], [\"red\", \"blue\", \"yellow\"]]\n",
"```\n",
"\n",
"#### 3. For each completion, compute the reward\n",
"\n",
"Assume we have a reward function that returns `1.0` if the completion is correct and `0.0` otherwise:\n",
"\n",
"```python\n",
"rewards = [[1.0, 0.0, 0.0], [0.0, 1.0, 0.0]]\n",
"```\n",
"\n",
"#### 4. Compute the advantage by normalizing the rewards within each group\n",
"\n",
"The advantage is calculated as follows:\n",
"\n",
"$$\n",
"\\hat{A}_{i,t} = \\frac{r_{i,t} - \\text{mean}(\\mathbf{r}_i)}{\\text{std}(\\mathbf{r}_i)}\n",
"$$\n",
"\n",
"This yields:\n",
"\n",
"```python\n",
"advantages = [[0.67, -0.33, -0.33], [-0.33, 0.67, -0.33]]\n",
"```\n",
"\n",
"#### 5. Compute the GRPO loss\n",
"\n",
"$$\n",
"\\mathcal{L}_{\\text{GRPO}}(\\theta) = -\\frac{1}{\\sum_{i=1}^G |o_i|} \\sum_{i=1}^G \\sum_{t=1}^{|o_i|} \\left[ \\frac{\\pi_\\theta(o_{i,t} \\mid q, o_{i,< t})}{\\left[\\pi_\\theta(o_{i,t} \\mid q, o_{i,< t})\\right]_{\\text{no grad}}} \\hat{A}_{i,t} - \\beta \\, \\mathbb{D}_{\\text{KL}}\\left[\\pi_\\theta \\| \\pi_{\\text{ref}}\\right] \\right]\n",
"$$\n",
"\n",
"#### 6. Update the model parameters\n",
"\n",
"Like in any other deep learning task, we can use the GRPO loss to update the model parameters using backpropagation.\n",
"\n",
"And we go back to step 1!\n",
"\n",
"---"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"So, let’s recap where we are so far:\n",
"We understand what RLVR is, we’ve defined our reward functions, we have a general grasp of how GRPO works, and our model is ready for fine-tuning.\n",
"\n",
"What’s missing? The data!\n",
"\n",
"Similarly, building a dataset with verifiable data isn’t trivial—but no worries, I’ve done it for you in this example:\n",
"👉 https://huggingface.co/datasets/qgallouedec/rick-physics-grpo\n",
"\n",
"Let's load it and check the first few samples."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from datasets import load_dataset\n",
"\n",
"dataset = load_dataset(\"qgallouedec/rick-physics-grpo\", split=\"train\")\n",
"dataset[0]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And now we're good? Not quite yet. Remember, in the previous tutorial, we said that data often needed to be prepared. Well, that's the case here. GRPO expects data to be *prompt-only*. Also, we want our data to be conversational. We'll need to process our dataset:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def format_dataset(example):\n",
" return {\"prompt\": [{\"role\": \"user\", \"content\": example[\"question\"]}]}\n",
"\n",
"dataset = dataset.map(format_dataset)\n",
"dataset[0]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"At this point, we finally have everything we need to start training.\n",
"Let’s see how to do that using `trl`!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from trl import GRPOTrainer, GRPOConfig\n",
"\n",
"args = GRPOConfig(\n",
" num_generations=16,\n",
" max_completion_length=512,\n",
" per_device_train_batch_size=4,\n",
" gradient_accumulation_steps=4,\n",
" num_train_epochs=10,\n",
" # Speedup and reduce memory\n",
" gradient_checkpointing=True,\n",
" bf16=True,\n",
" output_dir=\"data/SmolLM2-360M-Rickified-GRPO\",\n",
" # Logging\n",
" run_name=\"SmolLM2-360M-Rickified-GRPO\",\n",
" logging_steps=2,\n",
" log_completions=True,\n",
" num_completions_to_print=1,\n",
")\n",
"\n",
"trainer = GRPOTrainer(\n",
" model=\"qgallouedec/SmolLM2-360M-Rickified\",\n",
" reward_funcs=[format_reward, correctness_reward],\n",
" train_dataset=dataset,\n",
" args=args,\n",
")\n",
"trainer.train()\n",
"trainer.push_to_hub(dataset_name=\"qgallouedec/rick-physics-grpo\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"GRPO takes time to train, so I’ve done it in advance using a few optimizations and some extra compute—while keeping the process equivalent.\n",
"The trained model is available here:\n",
"👉 https://huggingface.co/qgallouedec/SmolLM2-360M-Rickified-GRPO\n",
"\n",
"Let's try it out!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"pipeline = transformers.pipeline(task=\"text-generation\", model=\"qgallouedec/SmolLM2-360M-Rickified-GRPO\")\n",
"\n",
"question = \"Sarah is cooking soup on the stove, and the heat is transferred from the hot soup at 90°C to a cooler room at 20°C. If the heat transfer is mainly due to convection and the rate of heat transfer is 250 Joules per minute, how much heat is transferred into the room over 10 minutes?\"\n",
"# The answer is 2500 J\n",
"prompt = [{\"role\": \"user\", \"content\": question}]\n",
"\n",
"generated_text = pipeline(prompt, max_new_tokens=512)[0][\"generated_text\"] # [{'role': 'user', 'content': \"How do ...\"}, {'role': 'assistant', 'content': \"<think>Alright, ...\"}]\n",
"completion = generated_text[1:] # [{'role': 'assistant', 'content': \"<think>Alright, ...\"}]\n",
"print(textwrap.fill(completion[0][\"content\"], width=120))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 🚀 Some recent findings about GRPO\n",
"\n",
"Recently, the scientific community has improved GRPO, so that today it's customary to use a slightly different version in practice. Two of the most important innovations are:\n",
"\n",
"#### 🤙 No need to use KL's divergence to regularize the drive\n",
"\n",
"```python\n",
"GRPOConfig(beta=0.0, ...)\n",
"```\n",
"\n",
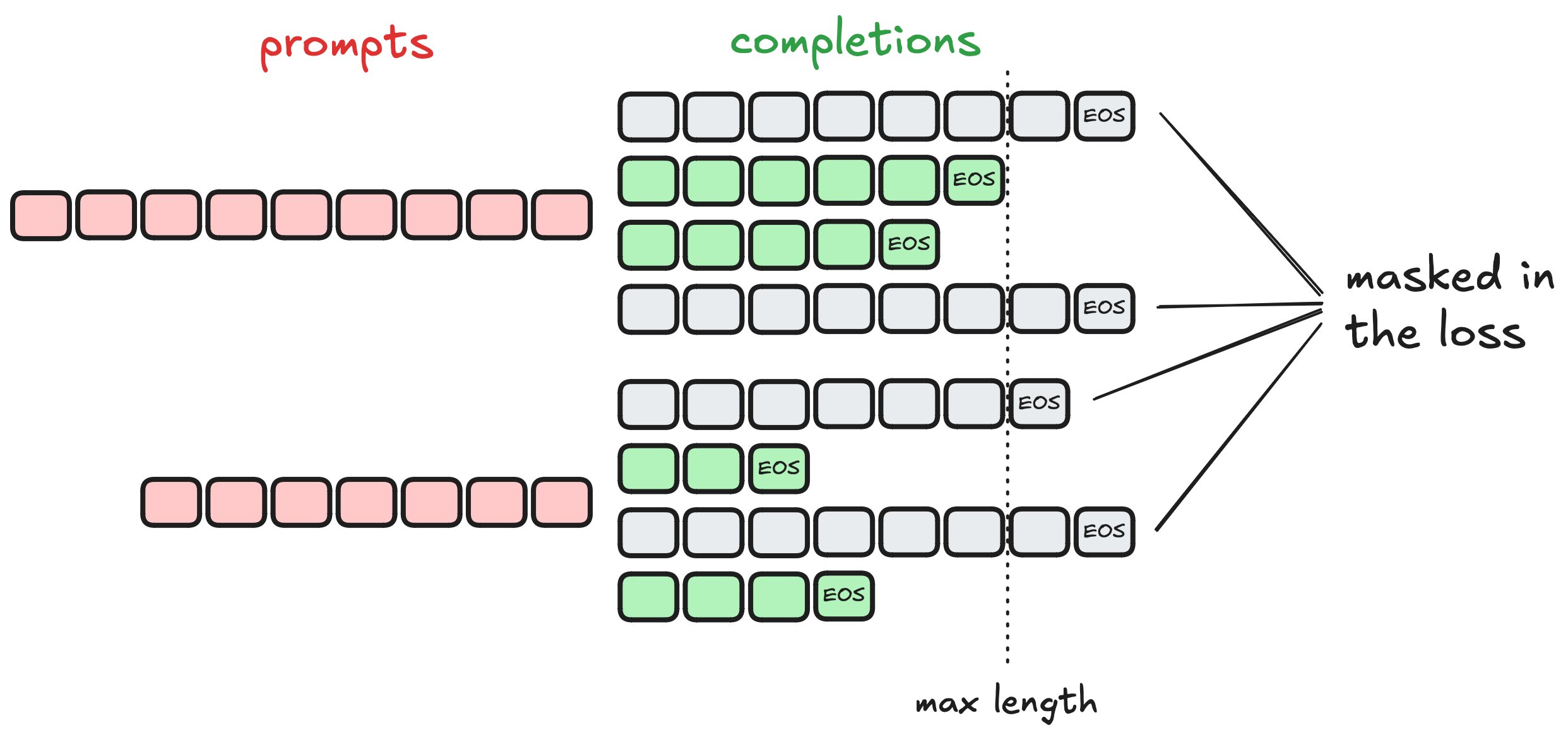
"#### 🙈 Generations that don't stick to the budget should be ignored\n",
"\n",
"\n",
"\n",
"### 🔮 What's next for GRPO?\n",
"\n",
"Are you tired of hearing about math?\n",
"\n",
"One of today's challenges is to use GRPO for more diverse tasks. This is now possible with TRL, you can use an arbitrary number of rewards. What's missing is verifiable data covering other fields.\n",
"\n",
"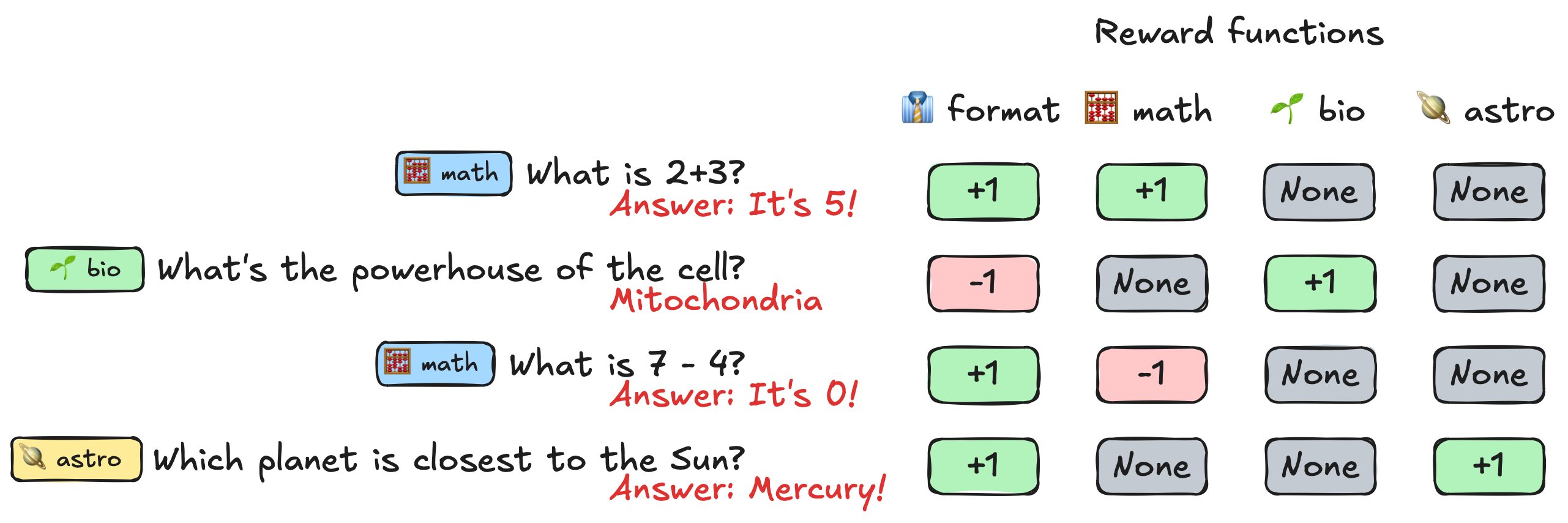"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "trl",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.12.9"
}
},
"nbformat": 4,
"nbformat_minor": 2
}